Translate Slovenian English: Smart AI Workflow for Accuracy
Ditch manual translation! Learn a smart AI workflow to translate Slovenian English content accurately and naturally from start to finish. Get precise results
You've probably done this before. A Slovenian email lands in your inbox, or a PDF from a supplier shows up five minutes before a meeting, and your first instinct is to paste it into a translator and hope the English comes out sounding less like a ransom note and more like something a real person wrote.
Sometimes that works.
Sometimes you get English that is technically understandable but feels off in all the ways that matter. The tone is wrong. A polite request turns stiff. A product description gets weirdly literal. A legal sentence becomes the kind of thing that makes everyone in the room suddenly very interested in “clarifying terminology.”
That's why I don't treat translate Slovenian English as a one-click task. I treat it like a workflow problem. The tool matters, sure. But the process matters more. If you clean the source, compare outputs, and edit with purpose, you can get fast, usable English without paying for a full human translation every single time.
Why Translating Slovenian to English Can Be Tricky
Slovenian looks approachable at first glance. It uses the Latin alphabet, so English speakers don't get that immediate “I can't even read this script” panic. But that familiarity is a trap. The actual difficulty begins once you move past the letters and into how the language behaves.
Slovenian has about 2.5 million speakers worldwide, with a literary tradition that reaches back to the first printed book in 1550, according to . That long written tradition matters because people aren't just using Slovenian casually. It shows up in education, public services, publishing, contracts, tourism, product materials, and cross-border communication. So the demand for decent Slovenian-to-English translation is steady, and “close enough” often isn't close enough.
The copy-paste problem
The main issue is that Slovenian packs a lot of meaning into word forms. Endings shift. Relationships between words aren't always expressed the way English expects. Word order can also move around more than many English-only readers realize.
That's where machine translation can get overconfident. It sees recognizable words, guesses a likely structure, and produces an English sentence that looks polished until you read it twice and think, “Wait, who is doing what to whom?”
Practical rule: If the English output feels slightly too formal, oddly abrupt, or suspiciously literal, the problem often started in the source sentence structure, not just in the model.
I see this most often in business messages and operational documents. A short Slovenian note can turn into English that sounds either robotic or bossy. Neither is ideal when you're trying to keep a client calm or a teammate aligned.
Why process beats luck
A lot of people still search for a magic button when they need to or handle another South Slavic language pair. In practice, these language pairs reward the same habit. Don't ask one system for one answer and ship it unchanged.
Use a workflow that catches the predictable failure points:
- Messy source text: Fix typos, formatting issues, and broken sentence fragments first.
- Unclear register: Decide whether the English should sound legal, neutral, sales-focused, or conversational.
- Terminology drift: Keep product terms, titles, and recurring phrases consistent.
- Literal phrasing: Watch for translations that are accurate word by word but wrong in tone.
The joke version is this: Slovenian is the kind of language that can make a translation engine look smart right up until it embarrasses you in front of your legal team.
Machine vs Human Translation The 2026 Verdict
The machine-versus-human debate is tired because most real work doesn't happen at either extreme. You usually have three choices: pure machine translation, AI-assisted translation, or full human translation. Each one has a place. The mistake is using the wrong one because it seemed faster in the moment.
A useful way to think about the current state of the field is historical. The shift in Slovenian-English machine translation didn't happen overnight. Research presented in Ljubljana in 2006 showed that data-driven statistical systems could outperform an adapted rule-based baseline for this language pair, as described in the . That was an important turning point. It's part of why today's AI tools are far more usable than the older “word salad generator” era.
Here's the quick visual version.

Pure machine translation
This is the fastest option. Paste text in, get English out, move on.
It's fine for low-risk material such as rough comprehension, internal notes, or deciding whether a document even deserves deeper review. It's not fine when tone, liability, brand voice, or technical precision matters.
What works
- Triage reading: You need to understand the general meaning now.
- Short operational text: Basic instructions or informal chat can be manageable.
- Volume scanning: You have too much content to review manually at first pass.
What breaks
- Context-heavy writing: Ambiguity stays hidden until it becomes a problem.
- Specialized vocabulary: One wrong term can distort the whole sentence.
- Politeness and tone: English can come out harsher than intended.
AI-assisted translation
This is the sweet spot for many. You use AI to generate a draft, compare alternatives, and then edit intentionally. You're not typing every sentence from scratch, but you're also not blindly trusting the first output.
That's the model I'd recommend for most business use cases. Product descriptions, support articles, internal documentation, subtitle drafts, and research notes all fit here.
A lot of professionals working across language pairs use this same middle lane, whether they're handling Slovenian or something equally nuanced like . The pattern is consistent. AI gets you speed. Human judgment gets you reliability.
Use machine output as a draft, not a verdict.
Full human translation
When accuracy is paramount, full human translation still wins. Contracts, regulatory text, litigation materials, sensitive public communications, and formal publishing all belong here.
That doesn't mean machines are useless in these projects. They're still useful for prep, terminology extraction, comparison drafts, and review support. But they shouldn't be making final meaning decisions on their own.
If you need a blunt verdict, here it is. Pure machine is acceptable for speed. Full human is necessary for high stakes. AI-assisted is the practical default for everything in between.
Your Smart Translation Workflow Start to Finish
A Slovenian sales deck lands in your inbox at 4:30 p.m. The English version needs to go out tomorrow. It came from a PDF, half the headings broke during export, one speaker note ended up inside the body text, and the product names are inconsistent across pages. That is not a translation problem yet. It is a workflow problem.
The teams that get reliable output do three things in order. They prepare the source, generate drafts with a purpose, and review in separate passes. A centralized setup matters because every handoff between OCR, chat windows, spreadsheets, and docs creates avoidable errors.
Pre-translate cleanup
Start by making the Slovenian readable and structurally sane.
If the source comes from subtitles, scanned files, audio transcripts, or copied tables, clean that first. I do not need perfect Slovenian at this stage. I need source text that preserves who said what, where sentences start and end, and which terms must stay fixed. For PDF-heavy jobs, the extraction step often decides whether the rest of the project goes smoothly. A messy file should be converted cleanly before translation, especially if your team is handling as part of the same production chain.
Check these items before you generate any English:
- Speaker attribution: transcripts need the right voice on the right line
- Structure: restore headings, bullets, tables, and paragraph breaks
- Noise: remove OCR errors, duplicated text, and broken punctuation
- Protected terms: flag brand names, feature names, legal references, and units
- Audience context: note whether the final English is for users, executives, regulators, or internal staff
That last point is easy to miss. A support article, a board memo, and event copy can all be accurate and still fail if they aim at the wrong reader.
Translation generation
Once the file is clean, generate drafts with different jobs. One draft should stay close to the Slovenian. Another should read like native English. If the text is technical, generate a third version that follows your approved terminology.
That comparison step saves time later because it exposes ambiguity early. If two drafts disagree on a clause, a date reference, or a modal verb, you know exactly where to review the source instead of polishing a hidden mistake.
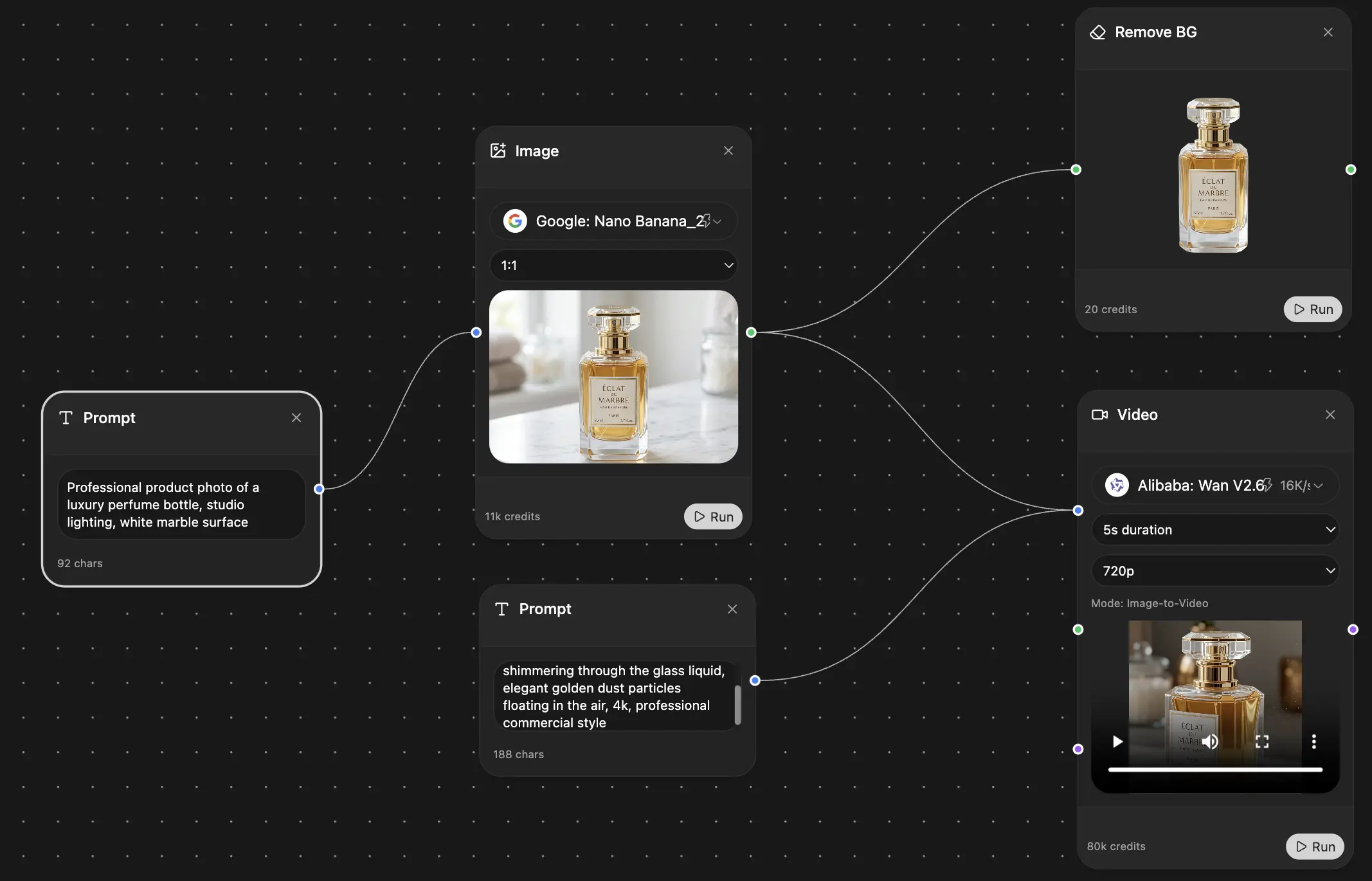
A centralized workspace helps here more than another standalone translator. keeps the source file, extracted text, draft outputs, and notes in one place, so the workflow stays controlled from preprocessing through post-editing. That matters on multilingual teams because version confusion usually starts outside the model, during copy-paste, file renaming, and side comments scattered across tools.
Here's the kind of setup I want on screen while working:

The same workflow logic carries across other difficult pairs. Teams refining run into many of the same operational issues, inconsistent formatting, unclear source segments, and the need to separate terminology control from style editing.
Post-editing polish
Post-editing is where cost control and quality control meet. If you skip it, machine translation stays cheap and risky. If you over-edit every sentence, you lose the efficiency that made AI useful in the first place.
I use two passes.
The first pass checks meaning. Confirm names, numbers, dates, negation, legal qualifiers, and clause relationships. Slovenian sentences can carry detail that English needs to reorganize, and that is where models can sound fluent while subtly shifting responsibility or timing.
The second pass checks whether the text works for the target reader. Read it as a finished English document, not as a bilingual exercise. Cut machine phrasing, flatten repetition, and replace literal wording that no English-speaking customer or colleague would ever use. For audience-sensitive material, the same cultural awareness that matters in also matters in localization. People notice tone long before they notice grammar labels.
A practical review checklist looks like this:
- Accuracy: facts, names, figures, links, and references match the source
- Consistency: repeated terms stay repeated for a reason
- Readability: sentences scan cleanly in English
- Purpose: the text sounds appropriate for the channel and audience
- Final formatting: headings, bullets, captions, and callouts survived the process
A professional Slovenian-to-English workflow is rarely about finding one perfect tool. It is about reducing friction between steps so the source stays clean, the drafts stay traceable, and the final English sounds intentional.
Preserving Tone Idioms and Cultural Nuance
Literal accuracy is not the finish line. It's the floor.
The hardest Slovenian-to-English problems usually show up after the words are technically translated. That's when tone, idioms, and cultural expectations start causing trouble. A sentence can be correct and still sound wrong. In business settings, that's often worse than a plain grammar mistake because nobody flags it immediately. They just decide your company sounds cold, clumsy, or oddly intense.

Why one model isn't enough
For nuanced work, I don't trust a single model output. MachineTranslation.com describes a workflow that runs text through 22 AI models and selects the translation most models agree on, and it pairs that approach with dictionary support for terminology. It also notes that PONS contains over a million headwords, phrases, and translations written by trained lexicographers, which is exactly why curated lookup still matters for specialized wording. You can read that on .
That consensus method makes sense for Slovenian because morphology and context can push different models toward different English choices. If several systems converge on the same phrasing, that's a useful signal. Not proof. A signal.
Here's where many teams go wrong:
- They accept the smoothest sentence, even if it drifts from the source.
- They overvalue literalness, which keeps the original structure but kills natural English.
- They skip terminology checks, especially when the sentence sounds plausible.
Idioms and tone need a second brain
Take an idiom like imeti mačka. A literal rendering gives you “to have a cat.” Funny, yes. Helpful, not so much. The actual meaning is a hangover. That kind of error is obvious when the idiom is colorful. It's less obvious when the phrase is ordinary but culturally loaded.
That's why human review still matters. You don't need to be a linguistics professor. You need to ask practical questions.
- What is the sentence trying to accomplish?
- How would an English speaker naturally say this in the same situation?
- Is the current phrasing preserving intent, or just preserving structure?
This overlaps with broader cultural awareness. If your translation will be used in travel, hospitality, cross-border services, or public communication, understanding how people interpret phrasing matters as much as vocabulary. CoraTravels has a useful read on , and the same mindset applies here. Good translation isn't just word transfer. It's behavior transfer.
When a sentence sounds “a bit weird” in English, treat that feeling as evidence. It usually means the translation kept the words but lost the social meaning.
If you want to get better at fixing these edge cases, it helps to think in terms of meaning layers, which is also why resources on are useful. The translation itself may be fine at the surface level while still missing the relationship between tone, intent, and context.
Translating for Specialized Fields like Tech and Legal
A Slovenian software string and a Slovenian contract clause can both look straightforward in a translation tool. They are not the same job.
In technical and legal content, wording carries instructions, liability, and scope. A slightly wrong term in a product manual creates support tickets. A softened modal verb in a contract can change what a party must do versus what it may do. That is why specialized translation needs a controlled workflow, not just a fast draft.

The checklist that prevents expensive revisions
For domain-specific Slovenian content, I start by reducing ambiguity before any model or translator touches the text. That saves more time than fixing inconsistent output later.
- Build a working glossary: Set approved English equivalents for repeated terms, interface labels, product features, legal concepts, and abbreviations.
- Define the reader: Engineers need clarity and consistency. Regulators need exact wording. End users need plain instructions.
- Flag non-translatables: Product names, statute references, company entities, and some acronyms should stay unchanged.
- Set style rules: Technical English should be direct and readable. Legal English should stay precise, even if the sentence gets less elegant.
- Assign a subject reviewer: A fluent editor is useful. A fluent editor with domain knowledge catches the mistakes that matter.
The trade-off is speed versus downstream risk. Teams save money with AI on the first pass, then lose it again if nobody controls terminology or checks whether the target text still matches the business purpose.
I also split specialized work into two operational categories. The first is terminology-heavy text, such as API documentation, safety instructions, compliance notes, and agreements. The second is format-heavy material, where the translation problem starts before language does. Scanned contracts, screenshot-based UI copy, image text, subtitles, and poor OCR all belong here.
Format problems break specialized translation faster than vocabulary problems
A legal clause copied from a clean document is one task. The same clause pulled from a bad scan is another. If the source text is broken, the translation draft will be broken in ways that are harder to notice.
That is why centralized workflows matter. Clean extraction, terminology control, draft generation, and post-editing should happen in one place or at least under one process owner. If your source arrives as a scan or locked document, start with . Otherwise you end up editing OCR errors, terminology errors, and style errors at the same time.
Multimedia adds another layer. Kapwing's shows how often this language pair now involves subtitles, dubbing, and speech-based workflows rather than plain documents. That affects tech teams localizing demos, researchers working from interviews, and service teams handling recorded instructions in the field.
The practical rule is simple. For specialized Slovenian-to-English work, treat translation as a managed production flow. Prepare the source, lock the terminology, generate the draft, then review with someone who understands the subject matter. That process gets professional results without paying expert human rates for every line.
Your AI-Powered Translation Ally
A good Slovenian-to-English result usually depends less on the model you pick and more on how tightly you control the handoffs.
I have seen the same source text produce two very different outcomes. In one setup, the translator copies text between separate OCR, chat, glossary, and editing tools, then spends half the review cycle fixing avoidable mistakes from formatting loss and inconsistent terminology. In the other, the team keeps cleanup, drafting, revision, and final approval in one system. The English reads better, the review is faster, and the budget goes further because human time goes to judgment calls instead of cleanup.
That is the primary value of an AI translation platform. It reduces context switching.
For Slovenian and English, that matters because small choices travel through the whole job. A mistranslated case ending, a dropped honorific, or an English sentence that sounds too literal can be corrected in post-editing, but only if the editor can still see the source, the draft, and the terminology notes together. Split those steps across too many tools and quality control gets sloppy under deadline.
Zemith fits that centralized workflow. Use it to prepare messy source material, generate a first draft, compare alternatives, and revise in the same working environment. AI handles speed. Human review handles meaning, tone, and risk.
If your current process involves constant copy-paste, scattered comments, and last-minute terminology fixes, the bottleneck is probably not translation skill. It is production design.
Explore Zemith Features
Every top AI. One subscription.
ChatGPT, Claude, Gemini, DeepSeek, Grok & 25+ more












Always on, real-time AI.
Voice + screen share · instant answers
What's the best way to learn a new language?
Immersion and spaced repetition work best. Try consuming media in your target language daily.
Voice + screen share · AI answers in real time
Image Generation
Flux, Nano Banana, Ideogram, Recraft + more

Write at the speed of thought.
AI autocomplete, rewrite & expand on command
Any document. Any format.
PDF, URL, or YouTube → chat, quiz, podcast & more
Video Creation
Veo, Kling, Grok Imagine and more

Text to Speech
Natural AI voices, 30+ languages
Code Generation
Write, debug & explain code
Chat with Documents
Upload PDFs, analyze content
Your AI, in your pocket.
Full access on iOS & Android · synced everywhere
Your infinite AI canvas.
Chat, image, video & motion tools — side by side
Save hours of work and research
Transparent, High-Value Pricing
Trusted by teams at
Free
No credit card required
- 100 credits daily
- 3 AI models to try
- Basic AI chat
Plus
- 1,000,000 credits/month
- 25+ AI models — GPT, Claude, Gemini, Grok & more
- Agent Mode with web search, computer tools and more
- Creative Studio: image generation and video generation
- Project Library: chat with document, website and youtube, podcast generation, flashcards, reports and more
- Workflow Studio and FocusOS
Professional
- Everything in Plus, and:
- 2,100,000 credits/month
- Pro-exclusive models (Claude Opus, Grok 4, Sonar Pro)
- Motion Tools & Max Mode
- First access to latest features
- Access to additional offers
What Our Users Say
Great Tool after 2 months usage
"I love the way multiple tools they integrated in one platform. Going in the right direction."
— simplyzubair
Best in Kind!
"The quality of data and sheer speed of responses is outstanding. I use this app every day."
— barefootmedicine
Simply awesome
"The credit system is fair, models are perfect, and the discord is very responsive. Quite awesome."
— MarianZ
Great for Document Analysis
"Just works. Simple to use and great for working with documents. Money well spent."
— yerch82
Great AI site with accessible LLMs
"The organization of features is better than all the other sites — even better than ChatGPT."
— sumore
Excellent Tool
"It lives up to the all-in-one claim. All the necessary functions with a well-designed, easy UI."
— AlphaLeaf
Well-rounded platform with solid LLMs
"The team clearly puts their heart and soul into this platform. Really solid extra functionality."
— SlothMachine
Best AI tool I've ever used
"Updates made almost daily, feedback is incredibly fast. Just look at the changelogs — consistency."
— reu0691