A Practical Guide to Research Data Management
Master research data management with this practical guide. Learn the data lifecycle, FAIR principles, and how tools like Zemith drive successful research.
At its most fundamental level, research data management is all about how you handle your data throughout a project's entire life. It’s the process of thoughtfully organizing, storing, protecting, and eventually sharing the information you collect and create. This isn't a one-and-done task; it's a continuous practice that turns a chaotic collection of files into a secure, accessible, and genuinely valuable asset. An actionable first step is to adopt a centralized platform like , which is designed to bring order to this process from day one.
Why Research Data Management Is Your Project's Foundation

Think of research data management (RDM) less like a chore and more like the architectural blueprint for your study. A building without a solid plan is unstable, and in the same way, research without a structured framework for its data lacks integrity, security, and long-term impact. Without it, you’re inviting a mess of disorganized files, risking catastrophic data loss, and making it nearly impossible to collaborate or verify your findings later.
A structured approach is about so much more than keeping your desktop tidy. It’s a core practice for producing credible, efficient research by creating a clear roadmap for how data is handled from the moment it's created to its final publication and preservation.
The Real-World Impact of Poor Data Management
Imagine spending months on intensive fieldwork, only to discover your data is locked in a proprietary file format your new analysis software can't open. Or picture the stress of a funder audit when you can’t quickly locate the exact dataset that supports a crucial finding in your paper. These aren't just minor inconveniences; they can derail your timeline and seriously damage your project's credibility.
Good RDM helps you get ahead of these problems. It ensures your work is not just reproducible but also transparent, which is key to building trust with funders, your peers, and the broader academic community. An actionable insight is to use a platform that supports open formats and makes data easily searchable, like Zemith, which helps prevent these exact issues.
Research data management is the proactive strategy that protects your most valuable asset: your data. It’s the difference between a project built on a solid foundation and one built on sand, ensuring your work can withstand scrutiny and contribute lasting value.
The Core Pillars of Effective Research Data Management
To better understand how these principles come together, let's break them down into their core components. Each pillar supports the overall strength and reliability of your research.
By focusing on these four areas, you create a robust framework that not only protects your work but also amplifies its potential impact.
Meeting the Demands of a Data-Driven World
The pressure to implement strong data practices is skyrocketing. The global enterprise data management market was valued at $110.53 billion in 2024 and is projected to expand at a rate of 12.4% annually through 2030. This growth is fueled by an almost unbelievable statistic: the world now generates around 328.77 million terabytes of data every single day.
For researchers, this data deluge means that casual, informal methods of handling files just don't cut it anymore. Fortunately, many are emerging to help automate and simplify these complex tasks. An actionable insight is to adopt an integrated platform like Zemith. It's built specifically to address these challenges, offering a unified workspace for document analysis, secure storage, and collaboration that makes excellent RDM an achievable goal for any researcher.
How to Navigate the Research Data Lifecycle
Think of research data like a living thing. It starts as a simple idea, grows as you collect and analyze it, and eventually matures into a published work that adds to our collective knowledge. Managing this entire journey is what research data management is all about.
It's helpful to see this process as a continuous cycle, not just a checklist of tasks. Every stage flows into the next. A seemingly small decision early on—like how you decide to name your files—can have a massive ripple effect weeks or months later. A solid, structured approach is the key to keeping your data coherent, safe, and valuable from start to finish.
Stage 1: The Planning Phase
Every great research project starts with a great plan. This isn't just about outlining your research questions; it’s about figuring out exactly how you're going to handle all the data you create. This is where you map everything out in a Data Management Plan (DMP), which acts as the North Star for your entire project.
Some key things to nail down in this phase include:
- Defining Data Types: What kind of data are you working with? Is it numerical, text-based, images, or something else entirely?
- Establishing Standards: How will you format your files, name your variables, and structure your folders? Getting this right from the start saves you from a world of confusion later.
- Outlining Storage and Security: Where will your data live, and what measures will you take to keep it protected?
An actionable insight is to use Zemith right from day one. Its built-in templates and guides walk you through creating a solid DMP, ensuring you’ve thought through these critical questions before you even think about collecting data. This foresight prevents countless future headaches.
This process flow shows the core steps of planning, storing, and sharing your data to keep your research organized and impactful.
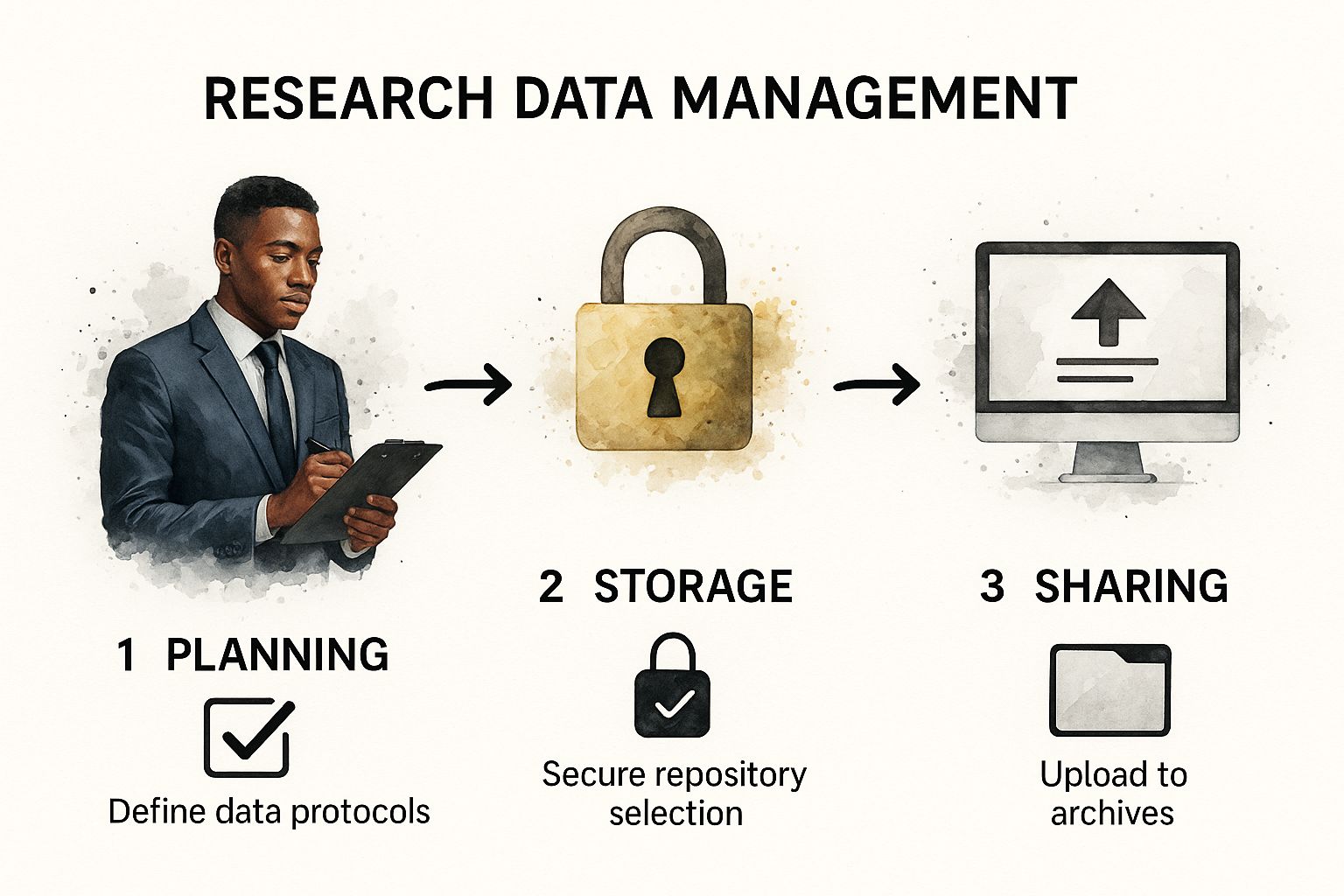
Stage 2: The Collection and Processing Phase
Once your plan is set, it's time to roll up your sleeves and get to work collecting and processing your data. This is usually the most hands-on part of the research lifecycle, where you’re gathering raw information and then cleaning and analyzing it.
During collection, data integrity is everything. You have to make sure your instruments are properly calibrated, your survey questions are crystal clear, and your methods are documented with painstaking detail. Both of these steps create a ton of new material—raw files, cleaned datasets, and analysis scripts. An actionable insight here is to centralize this material in a single workspace. Zemith allows you to store raw data, cleaned datasets, and analysis notes side-by-side, preventing information from getting siloed.
This is also where version control becomes absolutely essential. You need a rock-solid system for tracking changes to your data and code. A platform like Zemith offers built-in versioning, preventing that sinking feeling of accidentally overwriting hours of work or losing track of which dataset is the actual final version. Effectively navigating this phase often means bringing together different data sources, which requires a good handle on .
Stage 3: The Sharing and Preserving Phase
After the analysis is done and your findings are ready for the world, your data enters its final act. Sharing your data allows other researchers to verify your results, build on your work, and even ask new questions you hadn't considered. It multiplies the impact of your efforts.
Preservation takes it a step further. This involves preparing your data for long-term storage in a secure repository so that it remains accessible and usable for years, maybe even decades. This step is a cornerstone of the open science movement and is increasingly becoming a non-negotiable requirement from funding agencies.
By 2025, the total amount of global data is expected to hit a staggering 182 zettabytes. A huge chunk of this data explosion comes from research-heavy fields like healthcare, which is projected to generate 2,314 exabytes of data every year. With 48% of businesses now using AI to analyze these massive datasets, the need for well-managed, shareable data has never been more critical.
An actionable insight is to leverage platforms like Zemith that simplify this final stage. Its secure workspace keeps your data protected during collection and analysis. Then, its sharing features help you prepare your datasets with all the right metadata and documentation for easy publication in a repository. It makes the entire research lifecycle feel less chaotic and much more impactful. For those writing code during the analysis phase, learning can also significantly improve your productivity.
Building Your Data Management Plan
Let’s be honest. For many researchers, the Data Management Plan (DMP) feels like a bureaucratic hoop to jump through for funding. But thinking of it that way is a missed opportunity. A well-crafted DMP is your project’s strategic roadmap—a living document that guides every decision you make about your data from the very beginning.
Instead of a static file you create once and then forget, see your DMP as a dynamic blueprint. It’s what turns abstract ideas about good research data management into concrete, day-to-day actions. A strong DMP does more than just tick a box for a funder; it brings clarity to your entire project, heads off potential problems, and keeps everyone on the same page.
Key Questions to Build a Robust DMP
The real power of a DMP is that it forces you to answer the tough questions before they become full-blown crises. It's about being proactive. As you start drafting your plan, work through these fundamental points with your team.
- Data Types and Formats: What are you actually collecting? Is it qualitative interview transcripts, quantitative survey data, sensor logs, or software code?
- Metadata Standards: How will you describe your data so that you—or another researcher—can make sense of it later? Which metadata schema will you use?
- Storage and Backup Strategy: Where will the data live while the project is active? What’s your backup plan? Who needs access, and how will you manage permissions?
- Ethical and Legal Considerations: Are you working with sensitive personal information? You’ll need a clear plan for anonymization and for complying with regulations like GDPR.
- Roles and Responsibilities: Who on the team is in charge of what? Clearly defining who manages data at each stage prevents confusion and ensures accountability.
- Sharing and Preservation Plan: What parts of your data will you share publicly? And where will you deposit them to ensure they’re preserved for the long term?
An actionable insight is to use a tool that prompts these questions. Zemith’s DMP templates guide you through each of these points, ensuring your plan is comprehensive and setting your project up for a smooth ride.
A Data Management Plan is more than a requirement; it's a commitment to research integrity. It ensures that every dataset is not only collected but also contextualized, protected, and prepared for future discovery, turning your hard work into a lasting contribution.
From Checklist to Action with Zemith
Knowing what to put in a DMP is one thing. Actually creating and maintaining it as a team is another challenge entirely. The old way of emailing a Word document back and forth just doesn't cut it anymore—it’s a recipe for version control nightmares.
A modern, actionable approach is to use a platform like , which transforms the DMP from a static document into an interactive, collaborative workspace. Its features are built specifically to make this process intuitive. For example, Zemith provides integrated DMP templates that walk you through all the essential components, so you know nothing critical has been overlooked.
Here's a look at how Zemith’s workspace acts as a central hub for all your research documents and plans.

This kind of integrated environment means you can link your DMP directly to the datasets, documents, and team discussions it relates to. Everything is in one place, creating a single source of truth for the project.
With Zemith, you can manage the plan, work with your team, and store the data all in one spot. This not only makes it easier to comply with funder mandates but turns your DMP into a genuinely useful tool that grows and adapts right alongside your research. The plan becomes the active heart of your project, not just some file collecting digital dust in a folder.
Best Practices for Data Storage and Security
Let's be blunt: keeping your research data safe and sound isn't just a "good idea." It's a fundamental responsibility. Your data is the bedrock of your entire project, and protecting it from corruption, accidental loss, or a security breach is non-negotiable. Get this right, and you can focus on the actual research instead of worrying about a potential data disaster.
This goes far beyond just saving files to your laptop's hard drive or a basic cloud folder. A professional mindset means building a layered strategy that thoughtfully addresses where you store your data, how you back it up, and who can access it.
Choosing the Right Storage Solution
The first piece of the puzzle is picking the right home for your active data. An actionable insight is to adopt a hybrid approach from the start, combining local storage with a secure cloud solution.
Modern research needs more than generic file storage. A platform like Zemith gives you a secure, centralized cloud hub specifically built for the rhythms of a research project. It’s a dedicated workspace where your data is shielded by serious security protocols, yet always available to you and your authorized team members. To properly safeguard your work, it’s worth getting familiar with the that industry experts follow.
Any serious discussion about data safety has to include a rock-solid backup plan. The gold standard here is the 3-2-1 backup rule. It’s a simple but incredibly effective framework for making sure your data can survive just about anything.
Here’s how the 3-2-1 rule breaks down:
- Keep three complete copies of your data.
- Store these copies on two different types of media (like your computer's hard drive and a cloud server).
- Keep one of those copies in a different physical location (off-site).
An actionable insight is to automate this process. Using a platform like Zemith automatically provides secure cloud storage (your second media type) that is, by its nature, off-site (your third copy), helping you meet the 3-2-1 rule without even thinking about it.
Controlling Access and Protecting Your Data
Once your data has a safe home, the next step is managing who can see it and what they can do with it. Proper access control is absolutely critical, particularly when you’re dealing with sensitive or confidential information.
Here are three key practices you should build into your workflow:
- Version Control: Keeping a clear history of changes to your datasets, manuscripts, or analysis scripts is vital. It prevents someone from accidentally overwriting important work and gives you a transparent record of who changed what, and when.
- Granular Access Permissions: Work on the "principle of least privilege." People should only have access to the specific data they need to do their job. Zemith’s project-based workspaces are perfect for this, letting you grant specific permissions to each team member.
- Data Anonymization: If you're working with data from human participants, you have an ethical and legal duty to remove all personally identifiable information (PII) before you share or analyze it.
Putting these practices into action is a lot like applying —both are about systematically finding and fixing potential problems. An actionable insight is to use an all-in-one platform like Zemith that acts as a safety net, handling secure storage, automated backups, and fine-grained access controls so you can push your research forward with confidence.
Applying the FAIR Principles for Maximum Impact

To really get the most out of your research, your data needs to follow the FAIR principles. This isn't just some stuffy academic framework; it's a practical blueprint for making your data Findable, Accessible, Interoperable, and Reusable. Following these principles is what turns your data from a private file into a valuable asset for the entire research community.
Think of it this way. You could write a brilliant book, but if you just stick the manuscript in a box in your attic, who's going to read it? For that book to make a difference, it needs to be in a library with a unique catalog number (Findable), available for anyone to check out (Accessible), written in a language people can actually read (Interoperable), and clear for others to cite in their own work (Reusable).
Good research data management is what gets your data ready for the library.
How Zemith Helps You Implement the FAIR Principles
Putting these principles into practice might seem daunting, but modern tools are designed to make this much easier. An actionable insight is to adopt a platform like Zemith that has features directly supporting each pillar of FAIR, integrating them right into your workflow.
Here’s a practical look at how Zemith’s tools line up with the FAIR principles:
By building these actions into the research process from the start, you ensure your data is valuable and usable long after your project is finished.
Breaking Down the Principles
Making Your Data Findable
The first hurdle is simple: people need to know your data exists. This is where rich metadata and persistent identifiers are essential. An actionable insight is to use a tool that prompts you for metadata upon upload. Zemith, for instance, can guide you to add the necessary context (the "about" section) and assign a Persistent Identifier (PID) like a DOI, making your data discoverable in repositories.
Ensuring Data Is Accessible and Interoperable
Once someone finds your data, they need to be able to get to it. Accessibility means having a clear process for access. Interoperability ensures the data can actually be understood by both people and computers. An actionable insight is to standardize on open formats and use a platform that supports them. Zemith promotes the use of formats like .csv and .json and allows you to define vocabularies, so your data can be easily combined and analyzed by other tools.
The FAIR principles are more than a compliance checklist; they are a strategy for future-proofing your research. By making your data findable and reusable today, you are enabling questions to be answered tomorrow that you haven't even thought of yet.
Promoting Reusability for Lasting Impact
Ultimately, the goal is to make your data reusable. Clear documentation and licensing are non-negotiable for this. An actionable insight is to create documentation as you work, not after. A platform like Zemith makes this easy by letting you attach "readme" files and notes directly to datasets. It also includes tools to select a license (like Creative Commons), which removes any guesswork for other researchers.
This is especially critical in fields where technology is advancing quickly. For example, in clinical research data management, AI is changing everything. By 2025, AI is expected to handle up to 50% of data-related tasks in clinical trials, but this is only possible if the data it's trained on is meticulously documented and fully reusable.
Common Research Data Management Questions
Even the most seasoned researchers run into questions about managing their data. It's just part of the process. Getting ahead of these common sticking points can save you a lot of headaches later and help you build better research habits.
Let's walk through some of the most frequent questions we hear and offer some practical answers.
How Much Time Does Good Data Management Really Take?
There's no sugarcoating it: setting up a solid data management plan takes a bit of time upfront. But that initial investment pays for itself over and over. An actionable insight is to use tools that minimize this setup time. A platform like is built to shrink that initial commitment. By automating tedious tasks like version control, offering templates to get your DMP started, and handling backups automatically, it takes a lot of the manual work off your plate. This lets you get back to your research, fast.
Should I Create a DMP If My Funder Doesn't Require It?
Yes, absolutely. Think of a Data Management Plan as a roadmap for your own project. It's a fundamental part of doing responsible, professional research. An actionable insight is to use a tool that makes creating a "living DMP" easy. Instead of a static document, tools like Zemith allow your plan to grow and adapt right alongside your project, keeping you organized and on track.
Even when not required, a DMP serves as a vital internal guide. Researchers often overestimate the storage they'll need and benefit greatly from a plan that helps distinguish between essential data for deposit and auxiliary files that don't require formal preservation.
What Is the Difference Between Data Backup and Data Archiving?
This is a big one, and it's crucial to get right. Backups and archives sound similar, but they do very different jobs for your project.
- Data Backups are your safety net. They are copies of your active, in-progress data.
- Data Archiving is about the long game. It’s the process of storing your completed data securely for future reference.
An actionable insight is to use a system that handles both. A system like Zemith gives you a secure space for your active data with automated backups (your safety net), and then helps you package that data for a smooth handoff to a formal archive when your project wraps up (the long game).
Can I Just Use Google Drive or Dropbox for My Research Data?
While consumer cloud storage like or is great for personal files, they weren't built for the demands of serious research. They often lack funder-required audit trails, granular permissions, and integrated tools for your DMP. More importantly, they don't support the rich metadata that makes your data truly findable, accessible, interoperable, and reusable (FAIR).
The actionable insight is to choose a tool built for the job. A purpose-built platform like Zemith connects every piece of the research lifecycle in a secure, compliant environment that general-purpose storage can't replicate, saving you from compliance headaches and future data chaos.
Ready to stop juggling dozens of apps and bring true efficiency to your research? Zemith is an all-in-one AI platform that combines document analysis, a smart notepad, coding assistance, and deep research capabilities into a single, seamless workspace. See how you can streamline your entire research data management workflow at .
Explore Zemith Features
Every top AI. One subscription.
ChatGPT, Claude, Gemini, DeepSeek, Grok & 25+ more












Always on, real-time AI.
Voice + screen share · instant answers
What's the best way to learn a new language?
Immersion and spaced repetition work best. Try consuming media in your target language daily.
Voice + screen share · AI answers in real time
Image Generation
Flux, Nano Banana, Ideogram, Recraft + more

Write at the speed of thought.
AI autocomplete, rewrite & expand on command
Any document. Any format.
PDF, URL, or YouTube → chat, quiz, podcast & more
Video Creation
Veo, Kling, Grok Imagine and more

Text to Speech
Natural AI voices, 30+ languages
Code Generation
Write, debug & explain code
Chat with Documents
Upload PDFs, analyze content
Your AI, in your pocket.
Full access on iOS & Android · synced everywhere
Your infinite AI canvas.
Chat, image, video & motion tools — side by side
Save hours of work and research
Transparent, High-Value Pricing
Trusted by teams at
Free
No credit card required
- 100 credits daily
- 3 AI models to try
- Basic AI chat
Plus
- 1,000,000 credits/month
- 25+ AI models — GPT, Claude, Gemini, Grok & more
- Agent Mode with web search, computer tools and more
- Creative Studio: image generation and video generation
- Project Library: chat with document, website and youtube, podcast generation, flashcards, reports and more
- Workflow Studio and FocusOS
Professional
- Everything in Plus, and:
- 2,100,000 credits/month
- Pro-exclusive models (Claude Opus, Grok 4, Sonar Pro)
- Motion Tools & Max Mode
- First access to latest features
- Access to additional offers
What Our Users Say
Great Tool after 2 months usage
"I love the way multiple tools they integrated in one platform. Going in the right direction."
— simplyzubair
Best in Kind!
"The quality of data and sheer speed of responses is outstanding. I use this app every day."
— barefootmedicine
Simply awesome
"The credit system is fair, models are perfect, and the discord is very responsive. Quite awesome."
— MarianZ
Great for Document Analysis
"Just works. Simple to use and great for working with documents. Money well spent."
— yerch82
Great AI site with accessible LLMs
"The organization of features is better than all the other sites — even better than ChatGPT."
— sumore
Excellent Tool
"It lives up to the all-in-one claim. All the necessary functions with a well-designed, easy UI."
— AlphaLeaf
Well-rounded platform with solid LLMs
"The team clearly puts their heart and soul into this platform. Really solid extra functionality."
— SlothMachine
Best AI tool I've ever used
"Updates made almost daily, feedback is incredibly fast. Just look at the changelogs — consistency."
— reu0691