Myanmar to English Translation: A Practical 2026 Guide
Struggling with Myanmar to English translation? Our guide offers a practical workflow for accurate results, from script detection to post-editing with AI.
You've got a Burmese PDF on your screen. The text looks fine in the source file, but once you paste it into a random translator, the output turns into soup. Names drift. Sentences flatten. Technical terms come back sounding like fortune cookies written by a stressed robot.
That's a normal Myanmar to English translation problem, not a personal failure.
A lot of translation advice online assumes your source text is clean, standardized, and written in the kind of tidy language that academic benchmarks love. Real material is messier. It might be scanned, copied from chat, typed in mixed script, packed with local shorthand, or full of domain language that breaks generic tools. If you need a translation for business, research, legal review, operations, or media work, “close enough” usually isn't close enough.
The good news is that you can get much better results without building a custom language pipeline or calling in a linguistics department. The trick is to stop treating Burmese translation like a one-click task and start treating it like a workflow.
Why Burmese Translation Is Trickier Than You Think
Burmese looks deceptively simple to people who don't work with it often. Paste text in, get English out. That's the fantasy. In practice, Myanmar to English translation often falls apart because the source text itself carries ambiguity before the model even starts.
Burmese is one of those language pairs where context does a lot of heavy lifting. Informal wording, mixed-script text, regional usage, and domain-specific vocabulary can all push a translation engine off track. That's why the key question usually isn't whether a tool can translate Burmese at all. It's whether it can preserve meaning when the source is informal, complex, or dialect-heavy, which public-facing translation pages rarely explain well, as noted by .
Why generic translators struggle
A big part of the problem is historical. Myanmar to English translation has been a low-resource problem in AI research for a long time. An early ACL paper described the goal as producing correct phrase translations from a “very limited bilingual corpus,” which tells you the issue wasn't invented yesterday. It has been baked into the language pair for years, and it still affects quality today. If you want a plain-English primer on why meaning often gets lost before translation even starts, semantic context matters as much as vocabulary, and .
Practical rule: If the Burmese source includes slang, abbreviations, culture-bound phrasing, or specialized terminology, expect the first machine translation draft to be incomplete.
You see this most clearly in high-stakes material. A product sheet might mistranslate a specification. A research passage might flatten nuance. A legal paragraph might come back technically grammatical but logically wrong. That last one is especially dangerous because bad translations often look polished.
Where people lose accuracy
The common failure points are predictable:
- Context gets dropped: A word-level translation may ignore who's speaking, what's implied, or what register the sentence uses.
- Terminology wanders: The same term can appear in several English forms across one document.
- Mixed inputs confuse the model: A screenshot, OCR text, and copied chat text do not behave the same way.
- Dialect and informal phrasing break literal output: What sounds natural in Burmese can become stiff or misleading in English.
If you're translating for business or research, “readable” isn't the finish line. “Meaning preserved” is.
That's why copy-paste workflows fail so often. They assume the model should solve source quality, script issues, terminology management, and style in one shot. It usually won't.
Decoding the Script and Dialect
Before translating anything, identify what you're holding. This sounds boring. It also saves hours.

A lot of bad Myanmar to English translation starts with a bad assumption about the source. People think they have clean Burmese text. What they have is a font-encoded mess, a screenshot, a social media caption, or text with regional clues that a generic engine won't interpret well.
First check the script encoding
Myanmar text often shows problems at the encoding level. If the text looks garbled after copy-paste, or characters stack oddly, don't blame the translator yet. The issue may be script compatibility, especially if the text originated in older systems or was shared across devices.
Researchers have treated Myanmar-English translation as a low-resource challenge for more than a decade. A 2011 study explicitly worked from a “very limited bilingual corpus,” which is one reason preprocessing and linguistic handling have mattered so much for quality in this language pair. You can see that directly in the .
Here's the fast diagnostic pass I use:
Look at the source format
Is it a screenshot, PDF, Word file, web page, or chat export? Screenshots and scanned PDFs usually need OCR before anything else.Test a short sample
Paste one or two lines into a plain text editor. If characters warp or reorder, pause translation and inspect encoding.Check consistency
If one paragraph renders cleanly and another doesn't, the file may mix formats or pasted sources.Flag likely regional language content
If terminology doesn't look like standard Burmese, you may be dealing with regional usage or another language from Myanmar appearing alongside Burmese.
Then look for dialect clues
This part gets skipped all the time. Not everything labeled “Burmese” is standard written Burmese in a form that machine translation handles cleanly. Public tools often talk as if all input is one uniform language stream. It isn't.
Some practical clues:
- Unusually inconsistent vocabulary: Could signal regional phrasing or code-mixed text.
- Names and place references: These can hint at local usage that affects term choice.
- Speech-like sentence patterns: Casual spoken Burmese often behaves differently from textbook-style prose.
- Mixed media source: Audio transcripts and subtitles often carry slang and transcription noise together.
If your source starts as speech, transcript quality matters before translation quality does. A decent first move is to convert the audio cleanly and inspect the text before translating. Tools built for speech workflows can help with that, and is useful for thinking through the transcription side.
Don't translate a mystery file. Diagnose it first. You wouldn't repair a car by guessing which part fell off.
The Clean-Up Crew for Your Text
Once you know what the source is, clean it. This is not glamorous work. It's also where a lot of translation quality gets won.

Burmese text often arrives with formatting noise, OCR mistakes, broken line wraps, copied UI junk, or punctuation problems. If you feed that directly into a model, the model will still answer. It just won't answer well.
Clean input beats clever prompting
People love prompts. Prompts are fun. Cleaning source text is less fun, so it gets neglected. But for Myanmar to English translation, source cleanup usually matters more than writing a fancy “please translate accurately” instruction.
My basic prep workflow looks like this:
- Extract the text first: If the source is a scan or image, run OCR and inspect the result manually.
- Normalize formatting: Fix stray line breaks, duplicated headers, footers, bullets, and broken paragraph flow.
- Separate obvious sections: Keep headings, tables, notes, and body text distinct so the model doesn't blend them.
- Preserve names and terms: Mark company names, people, places, product labels, and technical strings so they don't get “creatively improved.”
- Split long blocks into manageable chunks: Dense walls of text increase drift and inconsistency.
If your source starts as a PDF, get it into editable text before trying anything clever. A clean extraction step reduces a lot of downstream pain, and is handy if your document is locked inside a scan or awkward layout.
What to fix manually
Some issues are worth touching by hand because the payoff is immediate.
Transliteration can help in narrow cases too. If a place name, person name, or specialized term keeps translating badly, keep the original and add a phonetic note for your own reference. That gives you a fallback when the English output starts guessing.
The model can't recover meaning that got destroyed during OCR or formatting cleanup. Garbage in still has excellent job security.
A little cleanup up front saves you from playing whack-a-mole with every sentence later.
Translating with an AI Powerhouse
The lazy workflow is one engine, one paste, one prayer. That's fine for checking a menu or a social post. It's weak for anything that needs accuracy.

For low-resource languages, translation quality depends heavily on preprocessing and model choice. One study on Myanmar translation reported up to 6 BLEU points of improvement over baseline systems through a hybrid approach using preprocessing, and it also reported a related neural benchmark of 31.2 BLEU, which is a useful reminder that setup choices materially affect output quality. The details are in the .
That research matches what practitioners already feel in the trenches. Different models fail differently. One might preserve technical meaning but sound stiff. Another might read smoothly but blur key terms. A third might do surprisingly well with noisy input and then randomly fumble names. That's why I don't like treating a single engine as truth.
Compare outputs instead of trusting one
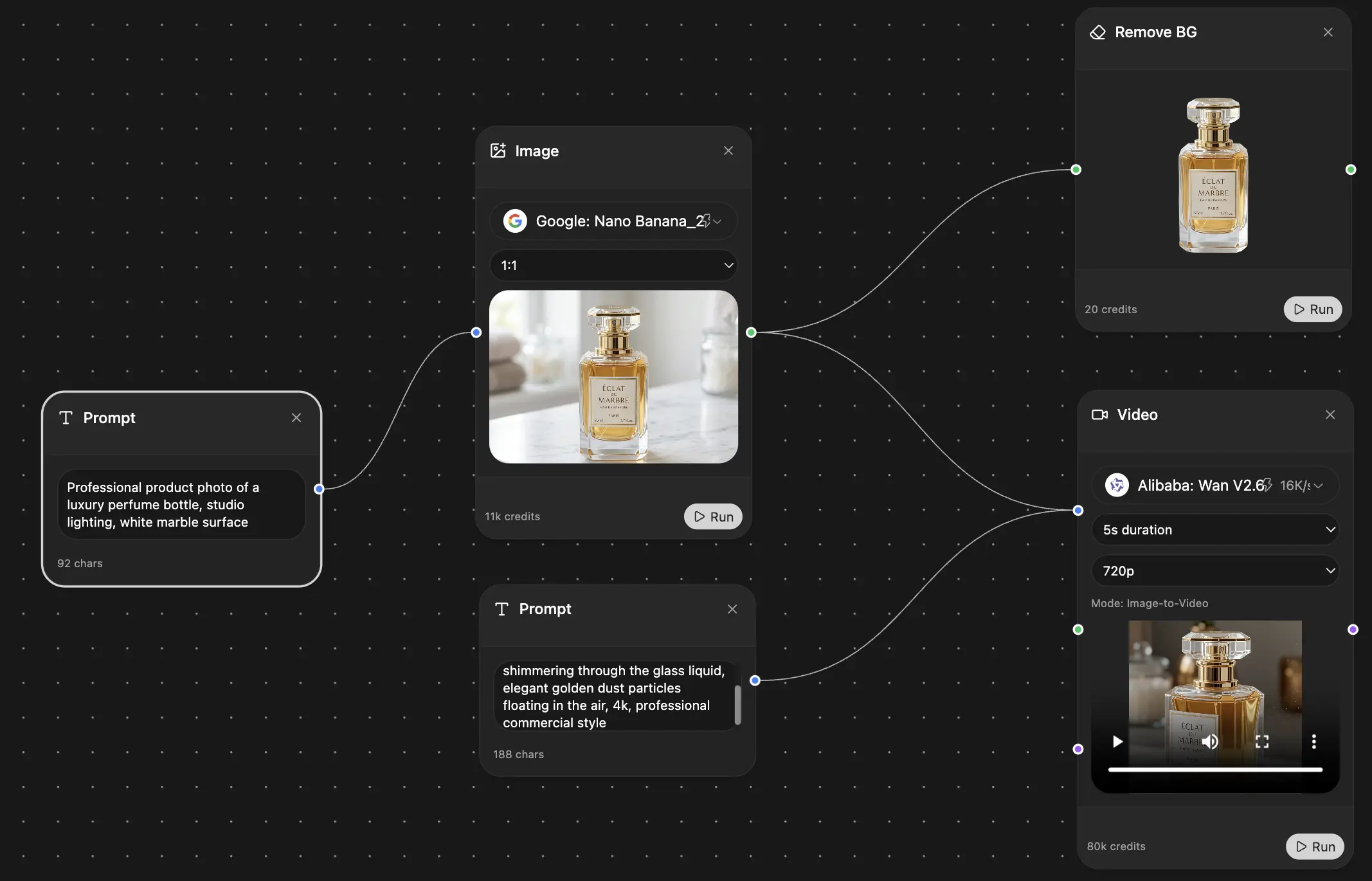
If you're using an all-in-one workspace such as , the practical advantage is simple. You can upload the cleaned text, run the same passage across multiple AI models in one place, and compare outputs without jumping across tabs and subscriptions. That's useful for Burmese because this language pair punishes blind trust.
A good comparison pass looks like this:
Run a short representative sample first
Don't start with the whole document. Test a paragraph that includes names, domain terms, and ordinary prose.Judge for meaning before style
The prettiest English version is not always the most faithful one.Watch repeated terms
If a model translates a key concept three different ways in one page, it's creating cleanup work.Check where it hesitates
Ambiguous lines, parenthetical notes, and list items often reveal a model's real weaknesses.
If you want a useful backgrounder on how these systems work under the hood, this explainer on is a solid read.
Use the model like a translator assistant
Don't just ask “translate this.” Give the model a job with boundaries.
Try instructions like these:
- Translate into clear professional English and preserve all named entities exactly as written.
- Keep legal or technical terms literal unless the source meaning becomes unclear.
- List any ambiguous lines separately instead of guessing.
- Maintain section structure and bullet hierarchy.
That last instruction matters more than people expect. Structure loss is one of the fastest ways a translation becomes unusable in operations or research.
For a related example of how comparing AI outputs can sharpen quality in another language pair, makes the same core point in a different context.
A quick visual helps if you want to see the workspace style in action:
The goal isn't to find a magical engine. It's to get the strongest draft with the fewest hidden errors.
From Machine Gibberish to Human-Readable English
Machine output is a draft. Sometimes it's a decent draft. Sometimes it reads like an intern translated the file during a fire drill.

Post-editing is where a rough translation becomes usable English. This is especially important for Burmese because a sentence can be technically translated while still sounding wrong, narrowing meaning, or bending tone in ways that matter.
A rule-based Myanmar-to-English system reported an 80% success rate on more than 1,200 simple sentences, but that result came from short, controlled input rather than messy open-domain documents. You can see why that matters in the . Real files contain ambiguity, domain terms, formatting junk, and half-finished thoughts. Human-led review is not optional.
What to edit first
Start with the parts that break trust fastest.
Meaning drift
Compare the English against the source for claims, obligations, directions, dates, and hedging language.Names and key terms
Verify personal names, place names, institutions, product labels, and specialized vocabulary.Tone and register
A research abstract, procurement memo, and interview transcript should not all sound the same.Sentence logic
Machines often produce grammatical English that still misstates who did what to whom.
If a sentence feels oddly polished but slightly off, inspect it harder. That's where the expensive mistakes like to hide.
A clean post-editing routine
I like a two-pass approach. First fix accuracy, then smooth the English.
Pass one for fidelity
Correct mistranslations, restore dropped qualifiers, and standardize repeated terminology.Pass two for readability
Rewrite clunky lines so they sound natural in English without adding meaning.
For this stage, AI-assisted rewriting helps. Once you've chosen the most faithful draft, use an editor to tighten phrasing, simplify awkward sentences, or make the tone more formal. If you need a practical way to handle that polishing step, is a good model for the workflow.
A few checks catch most of the ugly stuff:
- Read one paragraph aloud: awkward rhythm exposes machine phrasing quickly.
- Build a mini glossary: if a term matters, decide its English form once and reuse it.
- Flag uncertainty visibly: if a source line is ambiguous, note it instead of bluffing.
- Keep the source nearby: post-editing without source comparison turns into fiction with punctuation.
The goal isn't literary perfection. It's reliable English that preserves the source and doesn't embarrass you in front of a client, reviewer, or compliance team.
Your Complete Myanmar Translation Workflow
Good Myanmar to English translation isn't one action. It's a sequence.
First, diagnose the source. Figure out whether you're dealing with clean digital text, OCR output, a screenshot, mixed script, or something speech-derived. If you skip this, every later step gets shakier.
Second, clean the text before translation. Remove formatting junk, repair structure, separate sections, and protect names and technical terms. At this stage, a lot of avoidable errors are born, or prevented.
The four-part process that works
Here's the workflow in one pass:
Diagnose the source
Identify encoding issues, source format, and signs of regional or informal language.Prepare the text
Extract it cleanly, normalize structure, and reduce ambiguity before translation.Compare model outputs
Don't trust one engine by default. Test a representative sample and choose the most faithful draft.Post-edit for real use
Fix meaning drift, unify terminology, and rewrite awkward English so the final version reads naturally.
One clean workspace beats ten browser tabs and a notebook full of “which version was the good one?”
That's the operational advantage of an integrated setup. You can move from document intake to translation, comparison, and revision without losing context or scattering files across random apps. For business teams, researchers, journalists, and anyone handling multilingual content regularly, that isn't just tidier. It reduces mistakes.
The joke version is this: if your Burmese translation workflow currently includes “paste into three websites and hope one of them had a good day,” you're overdue for a system.
If you want a simpler way to handle the full workflow in one place, from document intake and AI comparison to rewriting and polishing, take a look at . It's built for people who are tired of juggling separate tools every time a tricky translation lands in their inbox.
Explore Zemith Features
Every top AI. One subscription.
ChatGPT, Claude, Gemini, DeepSeek, Grok & 25+ more












Always on, real-time AI.
Voice + screen share · instant answers
What's the best way to learn a new language?
Immersion and spaced repetition work best. Try consuming media in your target language daily.
Voice + screen share · AI answers in real time
Image Generation
Flux, Nano Banana, Ideogram, Recraft + more

Write at the speed of thought.
AI autocomplete, rewrite & expand on command
Any document. Any format.
PDF, URL, or YouTube → chat, quiz, podcast & more
Video Creation
Veo, Kling, Grok Imagine and more

Text to Speech
Natural AI voices, 30+ languages
Code Generation
Write, debug & explain code
Chat with Documents
Upload PDFs, analyze content
Your AI, in your pocket.
Full access on iOS & Android · synced everywhere
Your infinite AI canvas.
Chat, image, video & motion tools — side by side
Save hours of work and research
Transparent, High-Value Pricing
Trusted by teams at
Free
No credit card required
- 100 credits daily
- 3 AI models to try
- Basic AI chat
Plus
- 1,000,000 credits/month
- 25+ AI models — GPT, Claude, Gemini, Grok & more
- Agent Mode with web search, computer tools and more
- Creative Studio: image generation and video generation
- Project Library: chat with document, website and youtube, podcast generation, flashcards, reports and more
- Workflow Studio and FocusOS
Professional
- Everything in Plus, and:
- 2,100,000 credits/month
- Pro-exclusive models (Claude Opus, Grok 4, Sonar Pro)
- Motion Tools & Max Mode
- First access to latest features
- Access to additional offers
What Our Users Say
Great Tool after 2 months usage
"I love the way multiple tools they integrated in one platform. Going in the right direction."
— simplyzubair
Best in Kind!
"The quality of data and sheer speed of responses is outstanding. I use this app every day."
— barefootmedicine
Simply awesome
"The credit system is fair, models are perfect, and the discord is very responsive. Quite awesome."
— MarianZ
Great for Document Analysis
"Just works. Simple to use and great for working with documents. Money well spent."
— yerch82
Great AI site with accessible LLMs
"The organization of features is better than all the other sites — even better than ChatGPT."
— sumore
Excellent Tool
"It lives up to the all-in-one claim. All the necessary functions with a well-designed, easy UI."
— AlphaLeaf
Well-rounded platform with solid LLMs
"The team clearly puts their heart and soul into this platform. Really solid extra functionality."
— SlothMachine
Best AI tool I've ever used
"Updates made almost daily, feedback is incredibly fast. Just look at the changelogs — consistency."
— reu0691