Mastering Microservices Architecture Patterns for Resilient Systems
Discover microservices architecture patterns that boost scalability, resilience, and reliability with practical guidance and examples.
So, you're building a system out of dozens—or even hundreds—of small, independent services. It's a fantastic idea until you realize you're herding cats. You're bound to run into the same challenges over and over again. How do services talk to each other? What happens when one of them throws a tantrum and fails? How do you keep data consistent across the board without pulling your hair out?
This is where microservices architecture patterns come to the rescue. Think of them less as rigid rules and more as a collection of battle-tested blueprints from engineers who've already walked through the fire. They're the cheat codes for solving common problems in distributed systems. These patterns provide the strategies you need to manage everything from data consistency and service communication to fault tolerance, helping you build something that's scalable, resilient, and won't wake you up with a pager alert at 3 AM.
Moving Beyond Monolithic Headaches

Remember the old way of building software? We had one massive, tightly-coupled codebase where every single feature was tangled together. Deployments were a nerve-wracking, all-hands-on-deck affair because one tiny bug could take down the entire application. That was the reality of monolithic architecture, and frankly, it was exhausting.
A monolith is like a Jenga tower. It looks stable at first, but every change is a high-stakes gamble. Trying to pull out a single block—say, to update the payment module—risks bringing the whole structure crashing down. It makes innovation slow, risky, and incredibly stressful. It’s the "we can't touch that, it was built by Dave who left three years ago" part of the codebase.
The Great Migration to Microservices
The industry-wide shift to microservices isn't just a fad; it's a direct response to those monolithic migraines. Instead of a fragile Jenga tower, a microservices architecture is more like a set of LEGO bricks. Each service is its own independent, self-contained brick that can be worked on, updated, or replaced without disturbing the others.
This approach breaks a large application into a collection of smaller, loosely coupled services, and the advantages become clear almost immediately:
- Independent Deployment: You can push an update to the user profile service without ever touching the inventory service. This means faster, more frequent releases and happier engineers.
- Pinpoint Scalability: Is your search function getting hammered with traffic? Just scale that one service, not the entire application. It's far more efficient and cost-effective.
- Built-in Resilience: When one service fails, the blast radius is contained. A bug in the recommendations engine won't bring down your checkout process.
- Technology Flexibility: Your billing team can use Java while the data science team uses Python for their service. You can use the right tool for the job, every time, without starting a holy war.
If microservices are the LEGO bricks, then architectural patterns are the instruction manual. They provide the essential guidelines—how the bricks connect, how to build a stable foundation, and what to do when a piece doesn't fit—that keep your creation from falling apart.
Why This Shift Matters Now
The move away from monoliths is well underway. In fact, research shows that 85% of large companies have already adopted microservices, with an overwhelming 92% calling their transition a success. If you're looking for a deeper dive into making the switch, this guide on offers some great, practical advice.
Of course, this new world brings its own complexities. Managing dozens of services requires a different mindset and a new set of tools. As you navigate this landscape, having a unified workspace is a game-changer. That's where a platform like comes in, providing a single source of truth for your teams to collaborate on design docs, track dependencies, and manage the chaos. It turns a complex architectural puzzle into a manageable project.
Mastering Service Communication Patterns

So, you've built your city of independent services. Great. Now, how do they talk to each other? You need to lay down the roads, phone lines, and postal routes so they can all work together. If each service is its own specialized business, they can't just shout across the street. This is where service communication patterns come in—they are the essential telecommunication network for your entire architecture.
Get this part wrong, and you risk creating a "distributed monolith." It's a dreaded anti-pattern where your services are technically separate but so tangled up in dependencies that they can't operate independently. Choosing the right communication style is easily one of the most critical decisions you'll make.
Fundamentally, it boils down to two primary methods: synchronous and asynchronous communication. Nailing the difference is the key to building a system that's both responsive and incredibly resilient.
The Direct Line: Synchronous Communication
Synchronous communication is basically a direct phone call. When one service (the client) needs something from another (the server), it calls and waits for an immediate response before it does anything else. It's a direct, blocking, request-response conversation.
The most common way to pull this off is with REST APIs over HTTP. Let's use a restaurant kitchen analogy. A waiter walking directly to a specific chef and asking, "Is the steak ready?" is a synchronous request. The waiter just stands there, twiddling their thumbs, waiting for a "yes" or "no" before moving on.
- When It's a Good Fit: This pattern is perfect for real-time, user-facing operations where an immediate answer is non-negotiable. Think about a user trying to log in—the authentication service has to give an instant thumbs-up or thumbs-down.
- The Downside: The biggest risk here is tight coupling. If the chef is busy and doesn't answer, the waiter is stuck. In microservices, if the server service is slow or offline, the client service is blocked, which can trigger a domino effect of failures across the entire system.
Making synchronous communication work well hinges on designing clean, efficient APIs. For a much deeper dive, check out our guide on , which covers how to build interfaces that are both powerful and easy to work with.
The Message Board: Asynchronous Communication
Asynchronous communication is more like pinning a note to a message board. The sending service dispatches a message and immediately moves on to its next job without waiting for a reply. The message just sits there until the receiving service is ready to pick it up and process it. It's the "I'll get to it when I get to it" of service communication.
This is typically handled with a message broker like or . Back in our kitchen, this is like the waiter pinning an order ticket to a board. Any available chef can grab it, cook the dish, and put it on the pass. The waiter isn't stuck waiting; they're already off taking another table's order.
Asynchronous messaging is the backbone of loosely coupled systems. It allows services to operate independently, improving fault tolerance and overall system resilience. If one service is temporarily unavailable, messages simply queue up until it's back online.
While this approach does add new components like message queues into the mix, the payoff in scalability and robustness is enormous.
How Do Services Find Each Other?
In a dynamic cloud environment, services are constantly scaling up, shutting down, or getting updated. So how does one service know the "phone number" (the IP address and port) of another? Hardcoding this information is a recipe for disaster. This is the problem that service discovery solves.
Think of service discovery as a dynamic phonebook for your microservices. When a service starts up, it registers its current location with a central registry (like or Eureka). When another service needs to talk to it, it just asks the registry for the up-to-date location.
This pattern is non-negotiable for any cloud-native application. It allows your system to adapt to changes automatically without anyone having to intervene manually, ensuring your city of services always stays connected.
The API Gateway: Your System's Digital Bouncer
Think about a sold-out concert with thousands of fans. Would you let them all rush the stage from every direction? It would be chaos. Instead, you have a single, secure entrance with ticketing, security checks, and staff guiding everyone. This is exactly what the API Gateway pattern brings to a microservices architecture.
Without a gateway, every client—whether it's a mobile app or a web front-end—needs to know the exact address of every single microservice it communicates with. This creates a brittle, tangled web of connections, makes security a nightmare, and forces a ton of complex logic onto the client. An API Gateway changes the game by acting as the single front door for all incoming requests.
What Does the Bouncer Actually Do?
An API Gateway is much more than a simple passthrough. Like a good bouncer, it performs several critical jobs that protect and organize the entire system behind it. It works as a reverse proxy, fielding all API calls and routing them to the correct microservice.
This single entry point handles a variety of essential "cross-cutting concerns":
- Authentication and Authorization: It’s the first line of defense, checking every request to make sure it has the right "ticket" before letting it in.
- Request Routing: Like an usher at a theater, it intelligently directs traffic. Requests for
/profilego to the User Service, while/ordershead to the Order Service. - Rate Limiting and Throttling: It prevents any single client from overwhelming the system with too many requests, protecting your services from bugs or bad actors. It’s like telling someone, “Whoa there, buddy, slow down a bit.”
- Response Aggregation: Sometimes a client needs data from multiple microservices at once. The gateway can make those calls internally and stitch the responses together into one clean package for the client.
By taking on these responsibilities, the gateway dramatically simplifies both the client applications and the microservices. Your services can then focus purely on their core business logic, blissfully unaware of the complexities happening at the front door.
The Value of a Single Front Door
Putting an API Gateway in place delivers tangible benefits that are hard to ignore. It creates a vital layer of abstraction between your external clients and your internal service architecture. This decoupling is huge—it means you can refactor, update, or even completely re-architect your internal services without ever breaking the client applications that depend on them.
The API Gateway pattern transforms a potentially chaotic, many-to-many communication mess into a manageable, one-to-many model. It's the central nervous system for client interaction in a microservices architecture.
Of course, managing this critical component effectively is key. This is where modern tooling really helps. Platforms like offer integrated workspaces that give teams the visibility they need to manage and monitor these complex service interactions. Imagine having all your API contracts, documentation, and monitoring dashboards in one place instead of scattered across ten different browser tabs. That's the sanity a unified platform provides.
To really see the difference, let's look at how a system operates with and without a gateway.
Architectural Impact With vs Without an API Gateway
The table below shows just how much an API Gateway can simplify things like complexity, security, and client-side logic.
While the benefits are clear, it's important to remember that this pattern isn't a silver bullet. The gateway itself can become a development bottleneck or a new single point of failure if it isn't designed to be highly available and scalable. A solid strategy and proper management are non-negotiable for success.
Building Antifragile Systems with Circuit Breakers
In any distributed system, failure isn't an 'if' but a 'when'. It’s guaranteed. So, what happens when one of your shiny new microservices gets a cold? Does it just sneeze and infect your entire application, causing a cascading failure that takes everything down with it? Not if you have a Circuit Breaker on duty.
This pattern is your system’s first line of defense against temporary glitches and network hiccups. Think of it exactly like the electrical circuit breaker in your house. When there’s a power surge, it trips. This single action stops the surge from frying your expensive TV and everything else plugged in. It sacrifices a small part of the system (the power in one room) to protect the whole.
Understanding the Three States of Failure
The Circuit Breaker pattern is essentially a state machine that wraps around dangerous operations, like network calls to other services. It continuously monitors for failures and operates in one of three states. Understanding these states is key to seeing how it protects your application from itself.
It’s less of a bouncer and more of a concerned parent, telling a service, "You're not feeling well, just take a break for a few minutes. Go lie down."
This simple state-switching mechanism prevents a client service from repeatedly trying to call a service that is known to be unhealthy. This avoids wasting precious resources, like network connections and CPU cycles, on requests that are doomed to fail anyway.
Here's how it works:
- Closed State: This is the default, healthy state. The circuit is “closed,” and all traffic flows through normally. The breaker is quietly monitoring for failures, like timeouts or errors. If the number of failures crosses a pre-defined threshold, it trips.
- Open State: Once tripped, the circuit is now “open.” All requests to the failing service are immediately rejected without even trying to make the call. This is the protective state—it gives the downstream service time to recover without being hammered by constant requests.
- Half-Open State: After a configured timeout period, the breaker moves to this tentative state. It allows a single, trial request to go through to the downstream service. If that request succeeds, the breaker assumes the service has recovered and moves back to the Closed state. If it fails, the breaker trips again and returns to the Open state, restarting the timeout.
A Real-World Scenario
Picture an e-commerce site. The main product page calls a recommendation service to show "Customers also bought..." items. One afternoon, the recommendation service’s database becomes unresponsive. Without a circuit breaker, every user hitting the product page would trigger a request to this failing service.
Each of those requests would hang for 30 seconds before timing out. Soon, all the available threads on the product page's web server would be tied up, waiting. The product page crashes, and now nobody can buy anything. A small failure has caused a catastrophic outage.
With the Circuit Breaker pattern, the first few failures would trip the breaker into the Open state. Subsequent requests to the product page would get an immediate (though degraded) response. The recommendation section might be empty, but the core functionality—seeing the product details and adding to cart—still works perfectly. The application degrades gracefully instead of failing completely.
This pattern embodies the principle of "designing for failure." It accepts that things will break and provides a smart, automated way to contain the blast radius, ensuring one service's problem doesn't become everyone's problem.
Properly implementing these resilience patterns is a core part of a robust development lifecycle. Thoroughly testing how your system behaves during these failure modes is critical. For more on this, you can learn about essential that can help you validate your resilience strategies. It's a non-negotiable step for building truly antifragile, production-ready systems.
Solving the Distributed Data Dilemma
One of the biggest mental hurdles when moving to microservices is breaking up with the single, monolithic database. It was comfortable. It was predictable. All our data lived under one roof. But in the microservices world, each service is its own little kingdom, proudly owning its own data. This independence is fantastic for autonomy, but it introduces a thorny new puzzle: if data is scattered everywhere, how do you ever get a complete picture?
This is the distributed data dilemma, and it’s where some of the most critical microservices architecture patterns prove their worth. The foundational rule here is the Database per Service pattern. Each microservice manages its own private database, and no other service is allowed to access it directly. Think of it this way: the Orders service has its database, and the Customers service has its own. If the Orders service needs customer info, it can’t just sneak in the back door and read the Customers database. It has to ask politely through an API call.
This strict separation is non-negotiable if you want true loose coupling. It’s what ensures that a change to one service's data model doesn't create a domino effect of failures across your system. But it immediately brings up the next big question: how do you run a query that needs data from both services?
Getting Data to Cooperate Across Services
You can't just write a simple SQL JOIN across two different databases owned by separate services. It just doesn't work that way. This is where patterns like API Composition come in. An aggregator service—often the API Gateway or a dedicated backend-for-frontend (BFF)—acts as a coordinator. When a client needs a combined view, say, a customer’s recent orders, the aggregator calls the Customers service for user details and the Orders service for their order history. It then stitches the two responses together into a single, neat package before sending it back.
Another powerful approach is CQRS, which stands for Command Query Responsibility Segregation. This pattern splits your application into two distinct sides: the "Command" side for handling updates (like creating an order) and the "Query" side for handling reads. The Query side often uses a dedicated, denormalized read-model database that’s specifically optimized for complex queries. This separation is a massive performance win because it allows you to scale read and write operations independently.
To visualize how we keep these distributed services resilient, the Circuit Breaker pattern is a perfect example. It's designed to protect services from cascading failures when a downstream dependency is struggling.
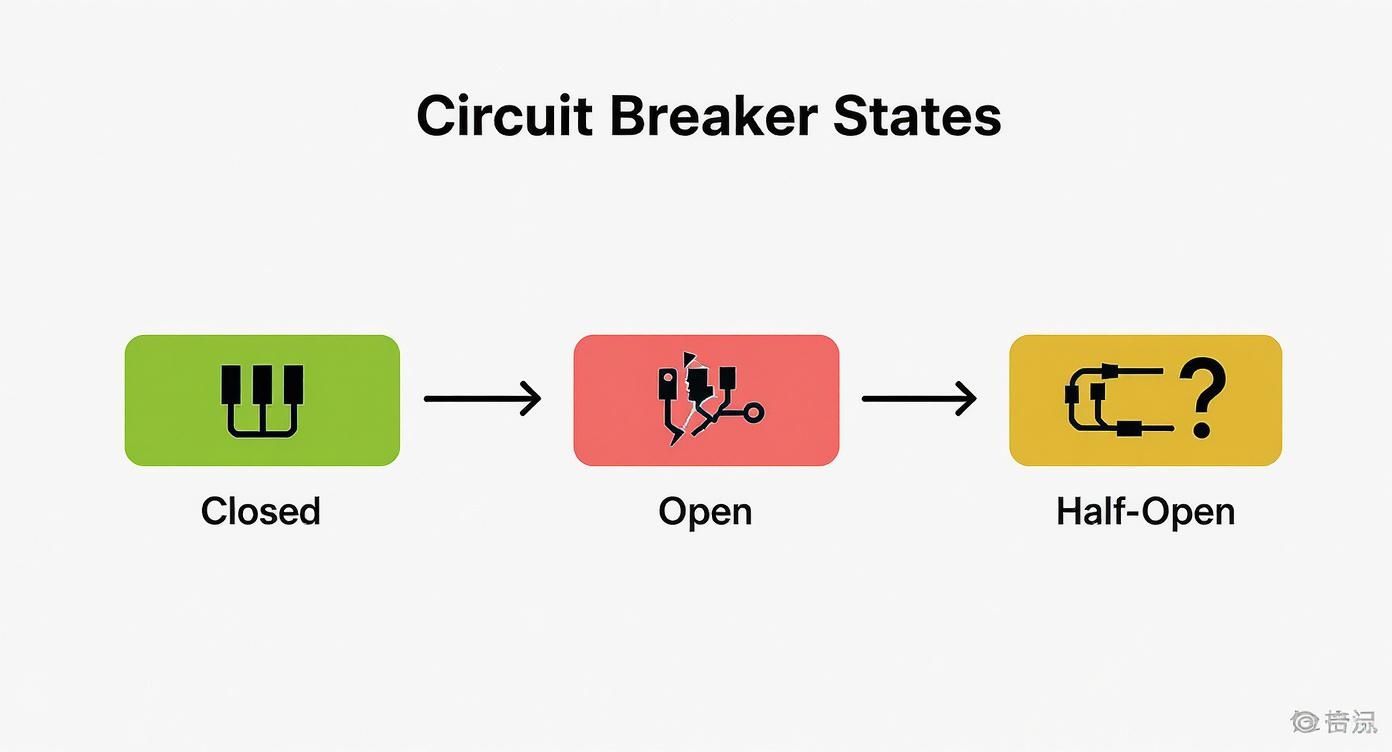
The flow from Closed (green) to Open (red) and Half-Open (yellow) shows how the system can automatically isolate a failing service, preventing a localized problem from becoming a system-wide outage.
Keeping a Perfect Record with Event Sourcing
For systems where auditing and historical data are critical, Event Sourcing offers a radical but incredibly powerful solution. Instead of just storing the current state of your data (like a final account balance), you store an immutable, append-only log of every single thing that ever happened. It's like a bank ledger; instead of just seeing you have $500, it shows every deposit and withdrawal that led to that balance.
With Event Sourcing, your data's state is the result of replaying a sequence of historical events. This provides a full audit trail, makes debugging easier, and opens up possibilities for deep business analytics.
The cloud has become the backbone for this kind of architecture. In fact, the global cloud microservices market was valued at USD 1.84 billion in 2024 and is projected to hit USD 8.06 billion by 2032. This explosive growth shows just how crucial mastering these advanced data patterns has become.
As you navigate the complexities of partitioned data, a firm grasp of becomes paramount for success. And before you can manage them, you need to structure them correctly; you can build a solid foundation by reading up on . Ultimately, these data patterns are the key to unlocking the full potential of your architecture while avoiding a distributed mess.
Where Microservices Are Headed: AI and Serverless
The world of microservices architecture is anything but static. Patterns like the Circuit Breaker and API Gateway have brought us a long way in building stable, resilient systems, but the next evolution is already here. We're now building applications that are not just resilient, but truly intelligent and hyper-efficient, thanks to two powerful forces: artificial intelligence and serverless computing.
This isn't just an incremental improvement. It represents a fundamental shift from systems that merely react to failure to those that can anticipate and prevent it before it ever impacts a user.
Smarter Systems That Heal Themselves with AI
Think about a standard Circuit Breaker for a moment. It trips after a few failures—a reactive measure. Now, imagine a version of that same pattern supercharged with AI. By constantly learning from telemetry data, it could spot the subtle signs of performance degradation and predict an impending service failure, rerouting traffic before the outage even happens.
This is the real promise of AI in the microservices world: creating systems that can heal and optimize themselves. AI and machine learning are being woven into the fabric of operations to automate complex tasks that once demanded hours of human effort, dramatically cutting downtime and boosting reliability.
This isn't just theoretical. In some real-world microservices management scenarios, AI-driven automation has already led to a 50% reduction in system downtime and delivered far quicker incident response times.
Taking Granularity to the Extreme with Serverless
Serverless computing, with platforms like leading the charge, takes the core principle of microservices—breaking things down—to its logical conclusion. Instead of deploying a service that's always running in a container, you deploy individual functions that spin up, execute, and disappear on demand.
It’s the ultimate "pay-for-what-you-use" model. You're only billed for the exact milliseconds your code is running, which opens up some incredible advantages for a microservices architecture:
- Unmatched Cost Efficiency: Why pay for idle servers? With serverless, that entire cost category can simply vanish.
- No More Server Management: Developers get to focus entirely on writing business logic, leaving the headaches of provisioning, patching, and managing servers behind.
- Effortless Scaling: The platform handles scaling from zero to thousands of requests and back down again automatically. This is a massive operational lift compared to configuring auto-scaling groups in a traditional setup.
The combination of AI, serverless, and microservices is pushing the boundaries of what's possible. It’s no surprise that the global serverless architecture market is projected to hit an incredible $21.1 billion by 2025. For a deeper dive, you can explore [Nucamp's analysis of microservices in 2025]( of-the-future).
Of course, embracing this future requires the right set of tools. The complexity of managing intelligent, event-driven functions can quickly become a major challenge. This is where an integrated workspace becomes non-negotiable. Platforms like provide a unified command center, giving teams powerful AI tools for coding, research, and optimization. It's all about making it easier to build and manage these next-generation applications, so you can focus on innovation instead of just keeping the lights on.
Frequently Asked Questions
When you start digging into microservices, the same questions pop up time and time again. It’s a big architectural shift, and it’s natural to wonder about the real-world hurdles. Let's tackle some of the most common queries I hear from teams making the switch.
What Is the Biggest Challenge When Adopting Microservices?
You might expect a deeply technical answer here, but honestly, the biggest challenge is almost always culture. Moving from a monolith, where one team often owns the entire codebase, to a world of distributed ownership and DevOps is a massive organizational shift. It’s less about code and more about changing how people work and collaborate.
From a technical standpoint, the toughest nuts to crack are usually distributed data consistency and building reliable, fault-tolerant communication between all your services. Getting these wrong early on can cause major headaches down the road, which is why choosing the right patterns from the start is so crucial.
How Many Microservices Is Too Many?
There's no golden number. If someone gives you a specific count, be skeptical. The "right" number of services is a moving target that depends entirely on your business domain and, just as importantly, your team structure. It's like asking "how many LEGO bricks should I use?" Well, what are you building?
A great starting point is to build slightly larger, coarser-grained services first. You can always break a service down later when you have a compelling reason.
So, when should you split a service?
- When it grows so large that a single team can't get their head around it anymore.
- When it has completely different scaling or data needs compared to the rest of the system.
- When multiple teams are constantly tripping over each other trying to make changes to it.
Are Microservices Always Better Than a Monolith?
Not at all. For a small team just starting out, a new project, or an application with a straightforward domain, a monolith is often the smarter choice. It's faster to build, simpler to deploy, and easier to reason about. The overhead of a distributed system only pays off once you hit a certain scale and complexity.
Many successful teams start with a "well-structured monolith." Think of it as an application with clean internal boundaries, making it much easier to carve out microservices later as the product and the organization grow. It’s a pragmatic way to get moving quickly without painting yourself into a corner.
Managing the complexity of a distributed system is no small feat. With , you get an AI-powered workspace that helps centralize your research, documentation, and even coding assistance. It gives your team the shared understanding needed to build and maintain sophisticated microservices architectures. .
Explore Zemith Features
Every top AI. One subscription.
ChatGPT, Claude, Gemini, DeepSeek, Grok & 25+ more












Always on, real-time AI.
Voice + screen share · instant answers
What's the best way to learn a new language?
Immersion and spaced repetition work best. Try consuming media in your target language daily.
Voice + screen share · AI answers in real time
Image Generation
Flux, Nano Banana, Ideogram, Recraft + more

Write at the speed of thought.
AI autocomplete, rewrite & expand on command
Any document. Any format.
PDF, URL, or YouTube → chat, quiz, podcast & more
Video Creation
Veo, Kling, Grok Imagine and more

Text to Speech
Natural AI voices, 30+ languages
Code Generation
Write, debug & explain code
Chat with Documents
Upload PDFs, analyze content
Your AI, in your pocket.
Full access on iOS & Android · synced everywhere
Your infinite AI canvas.
Chat, image, video & motion tools — side by side
Save hours of work and research
Transparent, High-Value Pricing
Trusted by teams at
Free
No credit card required
- 100 credits daily
- 3 AI models to try
- Basic AI chat
Plus
- 1,000,000 credits/month
- 25+ AI models — GPT, Claude, Gemini, Grok & more
- Agent Mode with web search, computer tools and more
- Creative Studio: image generation and video generation
- Project Library: chat with document, website and youtube, podcast generation, flashcards, reports and more
- Workflow Studio and FocusOS
Professional
- Everything in Plus, and:
- 2,100,000 credits/month
- Pro-exclusive models (Claude Opus, Grok 4, Sonar Pro)
- Motion Tools & Max Mode
- First access to latest features
- Access to additional offers
What Our Users Say
Great Tool after 2 months usage
"I love the way multiple tools they integrated in one platform. Going in the right direction."
— simplyzubair
Best in Kind!
"The quality of data and sheer speed of responses is outstanding. I use this app every day."
— barefootmedicine
Simply awesome
"The credit system is fair, models are perfect, and the discord is very responsive. Quite awesome."
— MarianZ
Great for Document Analysis
"Just works. Simple to use and great for working with documents. Money well spent."
— yerch82
Great AI site with accessible LLMs
"The organization of features is better than all the other sites — even better than ChatGPT."
— sumore
Excellent Tool
"It lives up to the all-in-one claim. All the necessary functions with a well-designed, easy UI."
— AlphaLeaf
Well-rounded platform with solid LLMs
"The team clearly puts their heart and soul into this platform. Really solid extra functionality."
— SlothMachine
Best AI tool I've ever used
"Updates made almost daily, feedback is incredibly fast. Just look at the changelogs — consistency."
— reu0691