Build Perfect File Organization System: From Folders to AI
Master your digital chaos! Learn to build an effective file organization system, from basic folders to advanced AI techniques, for peak productivity in 2026
Your desktop is packed with files named final, final-final, final-v2, and the dangerously confident FINAL_USE_THIS_ONE. Your downloads folder looks like a digital yard sale. You know the file exists. You just don't know where Past You hid it.
That mess costs attention more than anything else. It creates low-grade stress, slows decisions, and turns simple work into scavenger hunts. The worst part is that the usual advice is still “make more folders,” which is a bit like solving closet chaos by buying another hanger.
A modern file organization system should do more than store files neatly. It should help you find the right thing fast, understand what it belongs to, and keep useful context attached to it. That means structure still matters, but so do search, naming rules, and AI tools that can make sense of the pile when your folder discipline slips.
Escaping the Digital Junkyard
You probably don't need a lecture on digital clutter. You need a rescue plan.
A familiar scene: someone downloads a contract, edits a proposal, exports a PDF, grabs a few screenshots, and saves everything in three different places because they're in a hurry. A week later, they search by filename, then by date, then by vibe. Nothing. Now they're opening random folders like they're diffusing a bomb.

This gets worse when teams share drives. If everyone has a different filing habit, the folder tree turns into archaeology. One person files by client. Another by department. Another by month. Someone else leaves everything in Downloads and trusts destiny. If you're cleaning up before a platform move, this is exactly when you want to , because bad structure migrates just as enthusiastically as good structure.
The old fix isn't enough
Classic folder systems still matter, but folders alone don't solve modern work. Files now belong to multiple contexts at once. A deck can be sales enablement, board prep, and product messaging. A research PDF can support today's project and next quarter's strategy.
You don't need a prettier mess. You need a system that balances structure with retrieval.
That's why the better approach is a hybrid one. Use a clean folder structure for predictable storage, then layer in search, metadata, and AI context so you're not relying on memory or perfect filing behavior. If you want a practical look at that shift, this guide on is worth a read.
The goal isn't becoming the kind of person who color-codes USB cables for fun. The goal is simpler. You should be able to find what you need without muttering at your laptop like it betrayed you personally.
What Even Is a File Organization System
A file organization system is just a repeatable way to decide three things: where files go, what they're called, and how you'll find them later. If any one of those is fuzzy, the whole setup gets annoying fast.
The easiest analogy is a pantry. If pasta, cereal, spices, and dog treats all live wherever there was empty space at the moment, cooking becomes a treasure hunt. A good pantry system groups things logically, labels them clearly, and makes the common stuff easiest to reach. Files work the same way.
It's not just folders
A real system has a few parts working together:
- Structure: A small number of top-level folders or workspaces that reflect how you work
- Rules: Naming patterns, version habits, and simple decisions for where ambiguous files belong
- Tools: Search, tags, previews, and knowledge tools that help you retrieve files by meaning, not just location
If you only have folders, you don't have a full system. You have shelves.
Why folders became the default
The folder tree in common use today has deep roots. A foundational milestone came from the 1969 Multics operating system, which pioneered the hierarchical file system and moved computing away from flat catalogs toward nested directories, a shift that still shapes modern storage today, as described in this history of hierarchical file systems from Multics onward.
That parent-child folder model was a huge improvement over one giant undifferentiated list. It let people group files by project, purpose, or department. It scaled. It made sense. It stuck.
But there's a catch. The hierarchical model was built for storage logic, not for the messy reality of modern knowledge work where one file often serves several roles at once.
A folder answers “where does this live?” Modern work also needs “what is this about?” and “why does it matter?”
Why the AI era changes the game
Today, people don't just browse for files. They search by concept, ask questions across multiple documents, and want one workspace to connect notes, assets, drafts, PDFs, and conversations. That's why a good setup increasingly looks like a blend of classic organization and contextual retrieval.
If you think of your files as part of a broader knowledge environment, not just storage, this overview of connects the dots nicely.
A kitchen pantry still needs shelves. It just helps if the pantry can also answer, “Where's the cinnamon?” without forcing you to inspect twelve nearly identical jars.
The Four Main Filing Philosophies
There isn't one universal way to organize files. There are several philosophies, and each one solves a different kind of mess. The trick is picking the one that matches your work, not the one that looks prettiest in a YouTube thumbnail.

Hierarchical filing
This is the classic folder tree. You start broad, then go narrower.
Example:Clients > Acme > 2026 > Proposals
This works well when your work is stable and predictable. Finance, operations, legal, and admin-heavy teams often like it because it gives every file a home. It also makes onboarding easier because people can browse the structure and understand how the organization thinks.
The downside is rigidity. A file may fit more than one branch, and deep trees become a maze. People then create duplicates or save files in “temporary” spots that somehow become permanent.
Tag-based filing
Tags let one file belong to several categories at once. Instead of choosing one location, you attach labels like client, invoice, q2, approved, renewal.
That flexibility is excellent for research, content, and cross-functional work. A single document can be retrieved by topic, status, or audience. The problem is tag drift. If one person uses HR, another uses human-resources, and a third invents people-team, the system slowly turns into soup.
Tag-based systems live or die on consistency. Loose tags feel smart for about a week.
Chronological filing
Some people organize primarily by date. This is common for records, reports, receipts, exports, and recurring operational work.
Example:2026 > 2026-01 > 2026-01-15_Monthly-Report
This shines when sequence matters more than subject. It's also useful for files generated by routine processes. The drawback is that dates rarely tell the whole story. You might know when something was created and still have no clue what it was for.
Action-based filing
This method groups files by what needs to happen next.
Common folders look like:
- To review
- Waiting on
- Ready to send
- Archive
It's practical for active work, especially if you manage approvals, editing, or client deliverables. It also keeps momentum visible. The risk is that action status changes constantly, so the system needs regular maintenance or it gets stale.
Hybrid and database-driven thinking
Most effective setups combine these philosophies. You might use a shallow hierarchy for storage, dates in filenames for sorting, and status markers for active work. That's the sweet spot for many people.
A more advanced approach is database-driven organization, where files matter less as isolated objects and more as items inside a searchable, contextual workspace. In that model, the content of a document, the project it belongs to, and the conversation around it become just as important as its folder location. That's where tools like project workspaces, document libraries, and AI retrieval start earning their keep.
Here's a quick comparison:
If your current setup feels broken, it may not be because you're disorganized. You may just be using the wrong philosophy for the kind of work you do.
Golden Rules for Digital Sanity
Many users don't need a fancier system. They need a few rules they'll follow on a busy Tuesday.
The good news is that the basics are well-established. A widely cited best practice is to keep folder hierarchies to 3 to 4 levels and use dates in YYYY-MM-DD format, while filenames should stay under 32 characters and avoid spaces so they sort reliably and don't run into issues like Windows' 255-character path limit, as outlined in the University of Virginia's guide to .
Rule one, keep the tree shallow
If a file path feels like a hiking trail, it's too deep.
A shallow hierarchy forces you to make better top-level decisions. It also reduces the “where did we put that?” problem because people aren't digging through six nested folders named some variation of misc, old, or archive2.
A simple pattern works:
- Top level: Department, client, or project group
- Second level: Specific project or workstream
- Third level: File type, deliverable type, or time period
That's usually enough.
Rule two, make filenames sortable by default
Good filenames are tiny instructions to your future self. Bad filenames are cries for help.
Use a fixed pattern like:
- Date first:
2026-06-20 - Then subject:
Acme-Proposal - Then version if needed:
v03
A clean example:2026-06-20_Acme-Proposal_v03.docx
A messy example:proposal final FINAL newest use this one.docx
Practical rule: If a filename only makes sense while the project is fresh in your mind, it's not a good filename.
Rule three, create boring version habits
Version control doesn't need drama. It needs consistency.
Use one simple approach:
- For drafts in progress:
v01,v02,v03 - For approved output: add
Final - For obsolete files: move them to Archive instead of leaving them beside active drafts
That last part matters. Cluttered folders often aren't full of useful files. They're full of indecision.
Rule four, archive aggressively
People hesitate to archive because they think archive means gone. It doesn't. It means “not active.”
A dedicated Archive folder reduces noise without forcing deletion. It also protects active folders from becoming museums of every idea your team has ever had. If you want a broader operational lens on this, these are useful beyond file naming alone.
The best systems aren't complicated. They're predictable. That's what makes them survive contact with real work.
Building Your System With an AI Copilot
Cleaning up your files manually is possible. Doing all of it manually, forever, is where people give up.
That's the shift in modern file organization. It's no longer a question of manual versus automated. Recent guidance suggests the smarter question is how much manual organization is still worth doing in an AI-heavy workflow, since automation can save time in some cases but can also increase misfiling risk in work that needs judgment, as discussed in this piece on .

Step one, audit the mess
Start with reality, not ambition.
Open the places where files pile up most often:
- Desktop
- Downloads
- Shared drive hot spots
- Project folders everyone avoids touching
Look for patterns. Which file types repeat? Which projects produce the most duplicates? Which folders are active, and which are just historical sediment?
Don't rename everything at once. First identify the categories you already use naturally. Good systems usually emerge from observed behavior, not from a heroic burst of spreadsheet planning.
Step two, design a lightweight structure
Build a structure that matches how you retrieve files, not how you wish you did.
For many people, this means:
- A small set of top-level folders
- Consistent naming
- A clear Archive
- One place for incoming files that haven't been processed yet
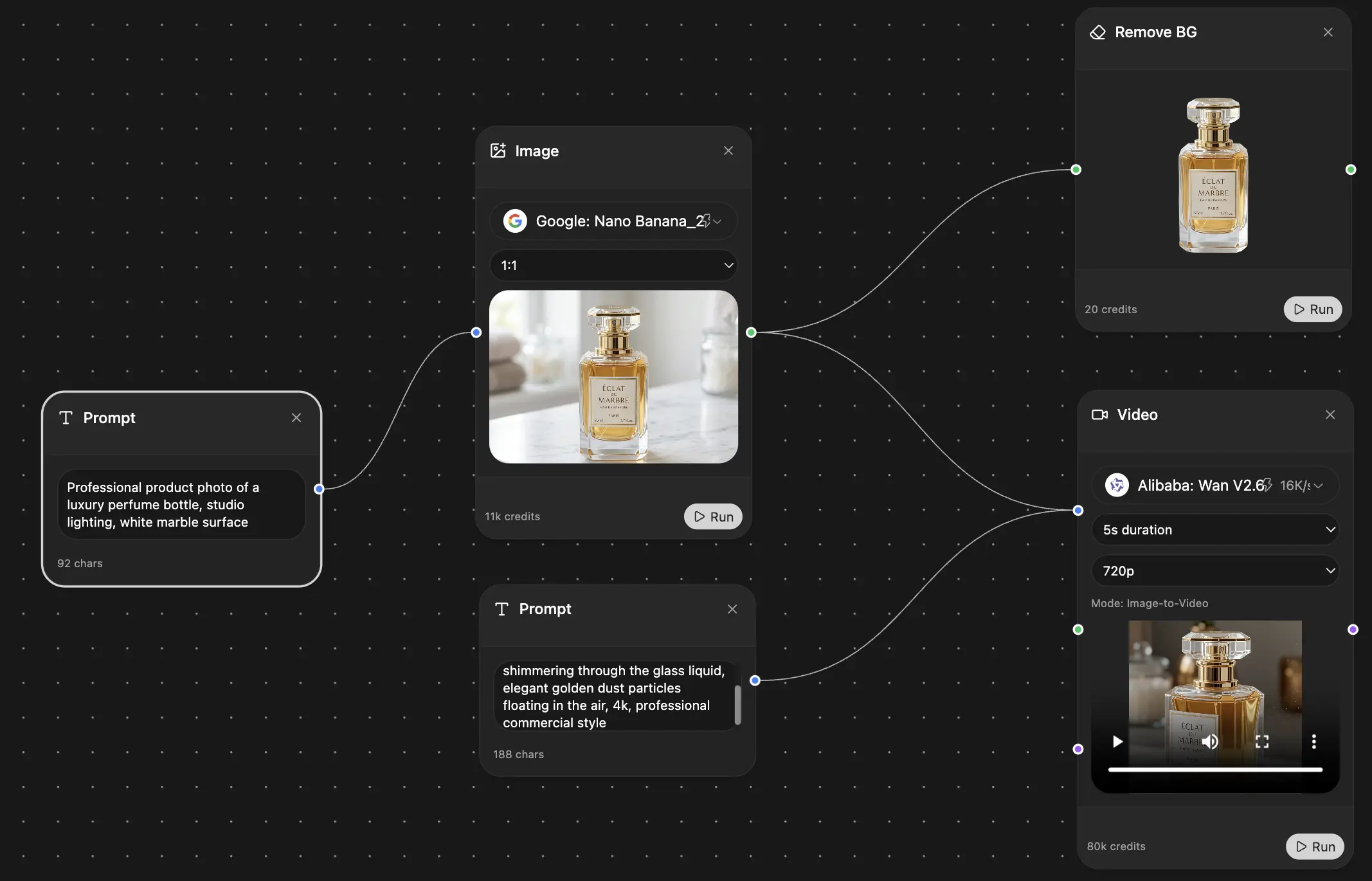
If you work across lots of notes, docs, and reference material, pairing that setup with an AI-first workspace can reduce the need for perfect filing. A good example is an that can keep documents and working context connected instead of scattering them across isolated apps.
Step three, migrate in batches
Don't reorganize your entire digital life in one sitting. That's how people end up rage-renaming 200 screenshots at midnight.
Use batches:
- Active projects first
- Shared team folders second
- Personal archive third
Anything unclear goes into a temporary triage folder. The point is momentum. Not purity.
Step four, add AI where it helps
The cheat code kicks in.
For active project work, Zemith can centralize files, chats, and project context inside shared workspaces using its Library and Projects features. That means your documents aren't just stored somewhere. They can be grouped by purpose, searched by content, and used as context for follow-up work without depending entirely on the folder they live in.
That kind of setup is especially useful when files come from multiple sources or when a document's meaning matters more than its exact storage path. If you care about local control or privacy-sensitive workflows, this guide to offers a useful companion perspective on how teams think about AI-powered retrieval.
Here's the key trade-off:
A quick demo helps if you want to see what this kind of workflow looks like in practice.
AI works best as a copilot, not a magician. Let it handle retrieval, context, and repetitive sorting support. Keep humans responsible for the judgment calls that shape the system.
Real World Blueprints for Different Brains
The best file organization system is the one you'll still use when you're busy, tired, and one Slack message away from chaos. Different kinds of work need different blueprints.

For developers
Developers usually do well with project-first organization.
A solid pattern:
- Project root
- Docs
- Src
- Assets
- Archive
Useful naming habits include release-oriented labels, dated exports for reports, and clear distinction between active code and generated artifacts. The mistake to avoid is mixing reference material, build outputs, and handoff docs in the same place.
For writers
Writers need a system that supports both creation and reuse.
Try:
- Client or publication
- Article or campaign
- Drafts
- Research
- Images
- Final
Tags or markers can help with editorial status, such as needs-review, pitched, or published. Writers often struggle when a research file belongs to multiple pieces. In that case, keep the source in the project where it's most useful now, then rely on search or workspace context to surface it later.
For researchers
Researchers usually need a more metadata-aware setup.
A practical structure:
- Topic or study
- Data
- Sources
- Analysis
- Outputs
- Archive
This keeps raw material separate from interpretation and finished deliverables. It also makes collaboration less painful because other people can tell what's primary evidence versus what's already processed.
Store raw files like they're evidence. Store working files like they're temporary. Store outputs like they'll be reused.
For teams
Teams need consistency more than cleverness.
A team-ready setup often starts with:
- Department or client
- Project
- Active
- Deliverables
- Archive
The naming convention matters more here than in solo work because everyone needs to understand the system without a tour guide. Shared work gets messy when each person brings their own filing religion.
Here's the practical upgrade across all four blueprints: use folders for stable storage, and layer on a workspace that can unify the assets around a project, topic, or deliverable. That way, the folder structure stays clean, but the work itself remains easier to search, reference, and continue.
Keeping the System Clean Without Losing Your Mind
Maintenance is where most file systems die. Not in the setup. In the slow creep of “I'll sort that later.”
The easiest fix is a short recurring cleanup. A weekly reset works well for many people: clear Downloads, move finished work to Archive, rename the handful of files that would confuse Future You, and delete obvious junk. Fifteen calm minutes beats one giant cleanup marathon fueled by regret and cold coffee.
The rule for ambiguous files
One of the biggest gaps in file-organization advice is how to handle files that fit multiple categories. Many guides suggest systems, but they often don't solve the messy reality that a file's usefulness changes over time, as noted in this discussion of .
Use a simple decision rule: file it where you'll look for it first.
If that still feels unclear, ask:
- What project is this helping right now
- Who is most likely to need it next
- Would I search by client, date, topic, or status
That gives you a practical answer fast. Not a perfect answer. A useful one.
Close enough is often enough
A modern system proves its worth. If your structure is clean, your naming is consistent, and your tools can search by content and context, you don't need to file every document with museum-grade precision.
That's also why workflow support matters. A system that combines tidy folders with retrieval and automation reduces the cost of small mistakes. If you're thinking beyond storage into repeatable upkeep, this overview of is a helpful next step.
A good file organization system doesn't turn you into a robot. It gives your brain fewer loose ends to hold. That's the ultimate benefit. Less searching, less second-guessing, and more time doing the work the files were supposed to support in the first place.
If your current setup depends on memory, luck, and opening six files to find the right one, it's time to upgrade the system. gives you a way to combine structured organization with AI-powered document context, so your files are easier to search, understand, and use without forcing perfect manual filing every time.
Explore Zemith Features
Every top AI. One subscription.
ChatGPT, Claude, Gemini, DeepSeek, Grok & 25+ more












Always on, real-time AI.
Voice + screen share · instant answers
What's the best way to learn a new language?
Immersion and spaced repetition work best. Try consuming media in your target language daily.
Voice + screen share · AI answers in real time
Image Generation
Flux, Nano Banana, Ideogram, Recraft + more

Write at the speed of thought.
AI autocomplete, rewrite & expand on command
Any document. Any format.
PDF, URL, or YouTube → chat, quiz, podcast & more
Video Creation
Veo, Kling, Grok Imagine and more

Text to Speech
Natural AI voices, 30+ languages
Code Generation
Write, debug & explain code
Chat with Documents
Upload PDFs, analyze content
Your AI, in your pocket.
Full access on iOS & Android · synced everywhere
Your infinite AI canvas.
Chat, image, video & motion tools — side by side
Save hours of work and research
Transparent, High-Value Pricing
Trusted by teams at
Free
No credit card required
- 100 credits daily
- 3 AI models to try
- Basic AI chat
Plus
- 1,000,000 credits/month
- 25+ AI models — GPT, Claude, Gemini, Grok & more
- Agent Mode with web search, computer tools and more
- Creative Studio: image generation and video generation
- Project Library: chat with document, website and youtube, podcast generation, flashcards, reports and more
- Workflow Studio and FocusOS
Professional
- Everything in Plus, and:
- 2,100,000 credits/month
- Pro-exclusive models (Claude Opus, Grok 4, Sonar Pro)
- Motion Tools & Max Mode
- First access to latest features
- Access to additional offers
What Our Users Say
Great Tool after 2 months usage
"I love the way multiple tools they integrated in one platform. Going in the right direction."
— simplyzubair
Best in Kind!
"The quality of data and sheer speed of responses is outstanding. I use this app every day."
— barefootmedicine
Simply awesome
"The credit system is fair, models are perfect, and the discord is very responsive. Quite awesome."
— MarianZ
Great for Document Analysis
"Just works. Simple to use and great for working with documents. Money well spent."
— yerch82
Great AI site with accessible LLMs
"The organization of features is better than all the other sites — even better than ChatGPT."
— sumore
Excellent Tool
"It lives up to the all-in-one claim. All the necessary functions with a well-designed, easy UI."
— AlphaLeaf
Well-rounded platform with solid LLMs
"The team clearly puts their heart and soul into this platform. Really solid extra functionality."
— SlothMachine
Best AI tool I've ever used
"Updates made almost daily, feedback is incredibly fast. Just look at the changelogs — consistency."
— reu0691