Learn to create podcast app: 2026 Guide
Learn how to create podcast app with our 2026 guide. Covers architecture, RSS, AI, monetization, launch & Zemith AI tips to build faster.
You’re probably in one of two situations right now.
Either you want to create podcast app software because existing players feel bloated, ugly, or too generic for your niche. Or you started building one already, then hit the part where RSS feeds get weird, audio playback acts haunted on mobile, and every “simple feature” turns into three backend jobs and a bug you can only reproduce on one Android phone from 2019.
That’s normal.
Podcast apps look straightforward from the outside. Search shows. Play episodes. Save progress. Done. In practice, they sit at the intersection of media ingestion, mobile UX, background processing, caching, analytics, and content rights. Add video, AI search, subscriptions, and offline playback, and suddenly your “weekend side project” starts acting like a product company.
The good news is that you don’t need to build the whole universe on day one. The teams that ship usually win by narrowing scope early, automating the boring setup, and choosing a few features that create a real wedge instead of cloning Spotify with a smaller budget and more caffeine.
Blueprint Your MVP Before Writing a Single Line of Code
Most podcast apps don’t fail because the code was ugly. They fail because the product tried to do too much before anyone proved users wanted the core behavior.
That matters even more in podcasting because creator supply is massive. 27,000 new podcast shows launch daily, and 44% fail to get past three episodes, according to . If your app depends on creators using advanced tools from day one, or listeners changing habits for features they never asked for, you’re building uphill.

Start with one job
A good MVP for a podcast app should answer one blunt question:
What is the one thing this app does better than a general-purpose podcast player?
Pick one lane:
- Niche listener app for a specific audience, such as business briefings, medical education, or private team podcasts
- Creator utility app focused on publishing, clipping, episode review, or feed analytics
- AI-enhanced listening app with summaries, searchable transcripts, and document-to-audio conversion
- Private audio knowledge app for internal content, research, or member-only feeds
If you can’t finish the sentence “people will switch because…”, your scope is still fuzzy.
Decide the feature floor
Here’s the minimum feature set I’d ship first for most listener-first apps:
That “usually no” for video is intentional. Video changes storage, moderation, bandwidth, transcoding, and player behavior. If you don’t need it, skip it.
Practical rule: if a feature adds a new subsystem, not just a new screen, it probably doesn’t belong in MVP.
Make the ugly decisions early
Founders love postponing foundational choices because wireframes are more fun. Don’t.
Choose these before development starts:
On-demand or live Podcast apps are mostly on-demand. If you add live audio, you’re building a different system with different expectations.
Public feeds or private feeds Private feeds mean access control, signed URLs, billing rules, and support tickets from users who forgot which email they used.
Audio only or audio plus video This one affects everything from storage costs to mobile data use.
Aggregator or owned content If you ingest public RSS, discovery matters. If you host your own catalog, rights and upload workflows matter more.
A lot of founders skip this step and go straight into Figma or code because it feels like progress. It isn’t. Product clarity is faster than rewriting your schema later.
If you want a good outside framework for narrowing scope, Rite NRG’s piece on a is useful because it forces you to separate “valuable” from “nice-looking.” For early product discovery, this walkthrough on the is also a practical way to stress-test your assumptions before the build starts.
Designing a Scalable Backend and Tech Stack
Podcast apps don’t need exotic architecture on day one. They need boring architecture that survives real usage. The trick is picking a stack that handles media workflows cleanly without trapping you in custom plumbing.
Development guidance for podcast apps is clear on one point. Creating an MVP first is critical for validating the concept through usability testing before committing to full-featured development and complex integrations, as noted in . That’s not theory. It’s self-defense.

A stack that won’t fight you
For a modern app, I’d usually start here:
Backend Node.js with Express, NestJS, or Fastify. Pick the one your team can maintain without creating a philosophy debate.
Database PostgreSQL for users, subscriptions, episode metadata, progress, bookmarks, and billing state.
Object storage S3-compatible storage for uploaded audio, cover art, waveform assets, transcripts, and derived files.
Queue and jobs BullMQ, RabbitMQ, or a managed queue for feed refreshes, transcription jobs, image processing, and notification tasks.
Mobile frontend React Native if one codebase matters. Native Swift and Kotlin if playback reliability and platform polish matter more than velocity.
Web app Next.js or another React stack for admin, creator dashboards, and desktop listening.
Don’t store blobs in your relational database
This is the mistake people make when they’re moving too fast.
Store metadata in PostgreSQL. Store audio and media files in object storage. Keep those concerns separate. Your API can return signed or proxied media URLs when needed, but your primary database shouldn’t become a warehouse for giant binary files and regret.
A simple data model usually covers the first release:
Generate the scaffolding, then review it like a grumpy senior engineer
AI offers substantial assistance. Boilerplate is expensive in attention, not just time. Generating CRUD routes, schemas, DTOs, migrations, and test stubs is a good use of an AI coding assistant. Let the model write the first draft. Don’t let it make architecture decisions unsupervised.
Prompts that work well are specific:
- “Create PostgreSQL tables for podcasts, episodes, users, subscriptions, and playback_progress with indexes optimized for episode lookup by podcast and publish date.”
- “Generate Express route handlers for podcast search, episode retrieval, and progress updates with validation and error responses.”
- “Write a queue worker that refreshes RSS feeds and performs idempotent episode upserts.”
Those prompts save setup time. They do not replace code review.
AI is great at accelerating repetitive structure. It’s much worse at noticing the subtle bug that only appears when a malformed feed updates while a user resumes playback offline.
If you’re defining your API contract early, this guide to is useful for keeping resource naming, pagination, and error handling consistent before client apps hardcode the wrong assumptions.
Build for the problems you actually have
I don’t recommend a microservices-first approach in general. A modular monolith is usually enough until separate scaling or deployment boundaries are obvious. You need clear modules, background jobs, solid logs, and observability. You do not need twelve services and a conference talk.
What works:
- A single deployable backend with clear domain modules
- Dedicated worker processes for feed sync and media jobs
- CDN in front of static assets
- Structured logs and alerting from the start
What usually doesn’t:
- Homegrown recommendation systems too early
- Over-abstracted media pipelines
- Building your own auth when managed auth is fine
- Treating podcast playback as “just another audio tag”
That last one gets people. Playback state, interruptions, lock screen controls, buffering behavior, and resume accuracy are product features, not implementation trivia.
Wrangling RSS Feeds and Streaming Audio
RSS is the plumbing behind almost every podcast experience, and it’s messy in the way only old, successful standards can be. The good news is that it’s still just XML. The bad news is that everybody interprets it a little differently.
If you want to create podcast app software that aggregates real-world shows, you need a parser that handles imperfect feeds without falling over dramatically like a Victorian novelist.
Parse defensively, not optimistically
At minimum, your ingestion layer should extract:
- Podcast-level fields like title, description, author, artwork, language, and feed URL
- Episode-level fields like title, GUID, publish date, enclosure URL, duration, and summary
- Change state so you can tell whether an item is new, updated, or missing
A practical Python example using feedparser looks like this:
def parse_podcast_feed(feed_url): feed = feedparser.parse(feed_url)
This is enough to start. It is not enough to trust blindly.
The real work is in the edge cases
Your importer needs to handle feeds that:
- omit GUIDs
- change enclosure URLs
- publish duplicate items
- send invalid dates
- ship giant HTML blobs in descriptions
- break image tags
- redirect unexpectedly
That means your import job should be idempotent. Running it twice shouldn’t create duplicate episodes or clobber good metadata with garbage.
A common pattern is:
- Fetch feed
- Parse feed
- Normalize fields
- Upsert podcast
- Upsert episodes by stable key
- Record import status and parse warnings
Bad feeds are normal. Treat parser errors as a product reality, not an exceptional event.
Stream audio like a media app, not a file downloader
A podcast app shouldn’t fetch the whole MP3 before playback starts. It should support range requests, buffering, and resume behavior that feels invisible to the listener.
That usually means:
If you proxy third-party audio through your own backend, be careful. It gives you control and analytics, but it also gives you bandwidth bills and more failure modes. Direct playback from the source is simpler. Managed proxying is cleaner when you need access control or transformation.
Transcripts make debugging and discovery easier
Transcript pipelines aren’t just an accessibility feature. They help with search, chaptering, summaries, and support. When someone says “episode playback jumped around,” transcript-aligned timing data often helps explain whether the issue is in the file, the player, or the metadata.
If you’re adding transcript support later, this overview on is a practical reference for how speech-to-text fits into a media product stack.
One joke before moving on. RSS will make you respect standards. It will also make you respect the people who ignore them and somehow still publish ten years of weekly episodes.
Building an Addictive Frontend Listening Experience
A podcast app lives or dies in the player.
Users will forgive a plain home screen. They won’t forgive playback controls that lag, progress that disappears, or an app that forgets where they stopped halfway through a long interview while they were entering a tunnel and questioning all career choices.

Reduce friction before adding delight
The engagement benchmark that matters here is harsh. Podcast listeners typically complete 65% or less of each episode, according to . That means the default listener experience already loses attention. Your UI has to help users continue, return, and skim intelligently.
The best frontend decisions are boring in a good way:
Mini-player always visible Don’t make users hunt for the current episode.
Reliable resume Save position locally first, sync second.
Skip controls that fit speech Standard music controls aren’t enough for spoken audio.
Playback speed that doesn’t sound mangled If 1.5x sounds like robots arguing in a hallway, users bail.
Episode notes that are readable Long descriptions need typography, link handling, and chapter structure.
The features that actually help retention
Not every retention feature needs machine learning and a fancy deck.
A few straightforward UI choices can improve completion behavior:
Chapter markers are especially underrated. If users know they can skip dead air, ads, or the intro banter they’ve heard seven times, they’re more likely to stay with the episode.
Good listening UX respects how people actually consume spoken content. They pause. They skim. They resume in the car. They forget what they were hearing.
Discovery should feel guided, not crowded
Most apps make discovery harder by dumping too much on the user. If your catalog is broad, use curation patterns that narrow choices instead of multiplying them.
Good patterns include:
- topic clusters
- “continue where you left off”
- fresh releases from followed shows
- short summaries under episode titles
- contextual recommendations based on what someone just finished
Bad patterns include endless carousels that all look the same and search that only works if the user already knows the exact show title.
Before locking your interface, run small usability sessions and watch people try basic tasks without help. You’ll learn more from one confused tester failing to add a show to their queue than from twenty internal opinions. This guide on is a helpful checklist for catching those issues before they become app store reviews.
Polish matters most in tiny moments
People remember tiny annoyances in media apps:
- the pause button that misses the first tap
- the player sheet that stutters when expanded
- cover art popping in late
- volume normalization that changes between episodes
- Bluetooth interruptions that resume incorrectly
That stuff isn’t glamorous, but it’s where trust gets built. A polished player earns the right to ship bolder features later.
Supercharging Your App With Next-Gen AI Features
Most podcast app guides stop at the obvious feature list. Search, subscriptions, downloads, playlists, maybe recommendations. That’s useful, but incomplete. The interesting gap is what happens when AI isn’t just a separate creator tool, but part of the app itself.
That gap matters because existing guides on building podcast apps often miss the trend of integrating generative AI for recommendations and content creation directly inside the app ecosystem, as discussed in .

AI features that feel useful instead of gimmicky
A lot of AI features sound impressive in demos and then end up annoying users. The useful ones reduce time, reduce friction, or surface context that listeners would otherwise miss.
The strongest candidates are:
Transcripts They improve accessibility, support in-episode search, and make chapters easier to build.
Summaries Great for long episodes when users want the gist before committing.
Semantic search Better than title search when someone wants “the segment where they discussed pricing strategy” instead of “episode 214.”
Auto-generated chapters Helpful when creators don’t provide structured timestamps.
Show notes generation Good for creator-facing workflows and cleaner episode pages.
Where AI creates actual differentiation
If you want to create podcast app software that stands out, AI needs to be part of the core value proposition, not a bolt-on sparkle effect.
Here’s the differentiation:
That last one is especially interesting for knowledge workers and teams. If users can turn internal documents, reports, or research into listenable audio, your app becomes more than a podcast player. It becomes an audio interface for information.
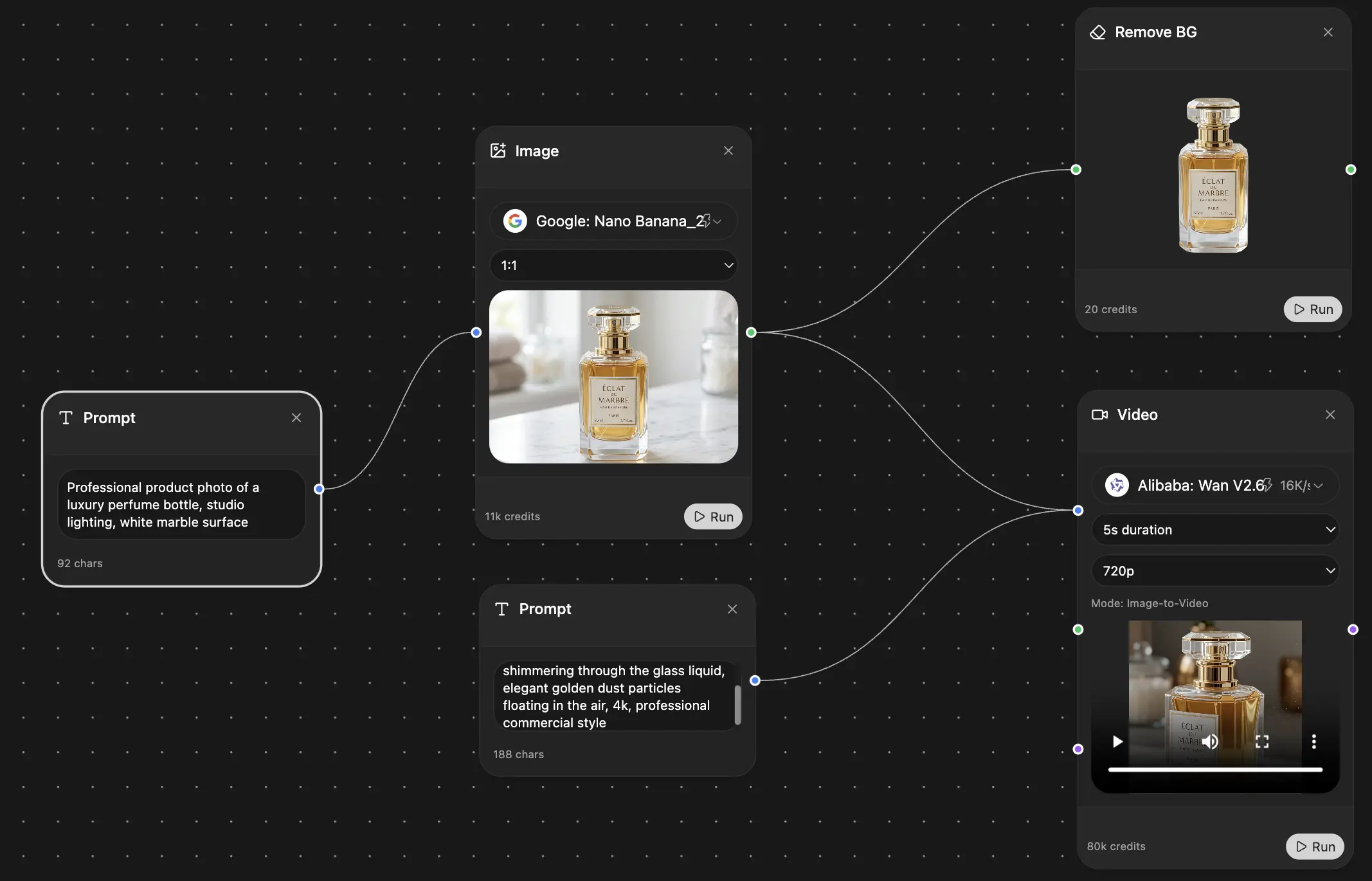
One way to support that workflow is using a platform that combines document handling, audio generation, code assistance, and creative tooling in one place. Zemith offers document-to-podcast conversion, coding assistance, and research tools inside a single workspace, which makes it practical to prototype transcript pipelines, generate summaries, and create private audio experiences without juggling multiple tools. For this use case, their is directly relevant.
Implementation advice from the trenches
A few guardrails matter when you add AI:
Run heavy jobs asynchronously Don’t block the episode page while a transcript or summary is being generated.
Store intermediate states Users should see “transcript processing” instead of a silent empty tab.
Allow regeneration AI summaries and chapters won’t always be right. Give admins a retry path.
Separate source truth from generated overlays Raw episode metadata should remain distinct from AI-generated content.
Design for failure If AI services time out, the core player still needs to work perfectly.
This is a good point to look at a practical example of AI-assisted content workflows in action:
Don’t let AI write checks your UX can’t cash
The fastest way to make your app feel fake-smart is to promise features like “ask anything about any episode” when your retrieval quality is shaky and your transcript alignment is loose.
A better pattern is constrained AI:
- summarize this episode
- find the section about hiring
- create a short recap
- extract action items
- convert this article into an audio episode
That’s focused. It’s testable. It’s useful.
The unfair advantage isn’t “using AI.” It’s choosing a few AI features that save users time every single session.
Your Go-To-Market Playbook Monetization and Launch
A lot of technical content teaches you how to build the app and then sort of wanders off when the hard business questions arrive. That’s a problem because guides about creating podcast apps rarely address sustainable monetization strategies, which leaves founders without much help on financial viability, as noted in .
A good launch plan ties product, pricing, analytics, and distribution together from the start.
Pick a monetization model that matches your product shape
Don’t start with “how do podcast apps make money?” Start with “what value are users paying for here?”
Common models:
Ad-supported listening Works when you have broad audience reach and enough inventory to make ad insertion worthwhile.
Premium subscription Good for ad-free playback, offline features, advanced discovery, private feeds, or AI tools.
Creator SaaS Better if your product serves publishers with analytics, feed management, clipping, or workflow automation.
Content membership Strong fit for niche networks, education, internal training, and paid communities.
If your app’s wedge is utility, charging listeners with no clear premium benefit is rough. If your wedge is private knowledge audio or AI-assisted listening, a paid tier makes much more sense.
Launch checklist that catches the obvious mistakes
Use this before release:
Beta test on real devices TestFlight for iOS. Closed testing on Android. Include bad networks, Bluetooth use, lock screen behavior, and long listening sessions.
Instrument the core funnel Track show follow, first play, completion drop-off, search usage, download starts, and resume behavior.
Prepare app store assets Screenshots, descriptions, keywords, and positioning matter more than most developers want to admit. If you need a quick primer on discoverability differences, this guide to is worth reading.
Write support docs before launch If users can’t restore purchases, import private feeds, or understand downloads, support debt appears instantly.
Plan post-launch fixes App launch isn’t the finish line. It’s the start of public debugging with ratings attached.
Ship a durable version one
The temptation is to launch with every feature you’ve dreamed about for six months. Resist it.
A durable v1 usually has:
Funny enough, users will tolerate a missing feature more than a broken core behavior. Nobody leaves a glowing review because your roadmap looked ambitious.
Conclusion Your Journey from Idea to App Store
Creating a podcast app isn’t a toy problem. It mixes product judgment, backend discipline, mobile polish, media quirks, and enough edge cases to keep you humble. That’s why the teams that ship well tend to simplify aggressively at the start and automate wherever they can.
The sequence that works is straightforward. Narrow the MVP. Build a backend that separates metadata from media. Treat RSS like an unreliable but necessary friend. Make the player feel dependable. Add AI where it changes the listening experience, not where it just decorates it. Then launch with a business model and measurement plan that match the product you built.
If you’re getting ready to market the app after release, this overview of is a useful complement to the technical work because it focuses on what happens after the build is live.
The main shortcut here isn’t magic code generation. It’s using better tools to compress the boring parts, validate faster, and spend your energy on the hard product choices. That’s where podcast apps are won.
If you want one workspace for research, coding help, document handling, and turning text into audio content, take a look at . It’s a practical option for teams building AI-assisted media workflows without juggling a pile of separate tools.
*Explore Zemith Features
Every top AI. One subscription.
ChatGPT, Claude, Gemini, DeepSeek, Grok & 25+ more












Always on, real-time AI.
Voice + screen share · instant answers
What's the best way to learn a new language?
Immersion and spaced repetition work best. Try consuming media in your target language daily.
Voice + screen share · AI answers in real time
Image Generation
Flux, Nano Banana, Ideogram, Recraft + more

Write at the speed of thought.
AI autocomplete, rewrite & expand on command
Any document. Any format.
PDF, URL, or YouTube → chat, quiz, podcast & more
Video Creation
Veo, Kling, Grok Imagine and more

Text to Speech
Natural AI voices, 30+ languages
Code Generation
Write, debug & explain code
Chat with Documents
Upload PDFs, analyze content
Your AI, in your pocket.
Full access on iOS & Android · synced everywhere
Your infinite AI canvas.
Chat, image, video & motion tools — side by side
Save hours of work and research
Transparent, High-Value Pricing
Trusted by teams at
Free
No credit card required
- 100 credits daily
- 3 AI models to try
- Basic AI chat
Plus
- 1,000,000 credits/month
- 25+ AI models — GPT, Claude, Gemini, Grok & more
- Agent Mode with web search, computer tools and more
- Creative Studio: image generation and video generation
- Project Library: chat with document, website and youtube, podcast generation, flashcards, reports and more
- Workflow Studio and FocusOS
Professional
- Everything in Plus, and:
- 2,100,000 credits/month
- Pro-exclusive models (Claude Opus, Grok 4, Sonar Pro)
- Motion Tools & Max Mode
- First access to latest features
- Access to additional offers
What Our Users Say
Great Tool after 2 months usage
"I love the way multiple tools they integrated in one platform. Going in the right direction."
— simplyzubair
Best in Kind!
"The quality of data and sheer speed of responses is outstanding. I use this app every day."
— barefootmedicine
Simply awesome
"The credit system is fair, models are perfect, and the discord is very responsive. Quite awesome."
— MarianZ
Great for Document Analysis
"Just works. Simple to use and great for working with documents. Money well spent."
— yerch82
Great AI site with accessible LLMs
"The organization of features is better than all the other sites — even better than ChatGPT."
— sumore
Excellent Tool
"It lives up to the all-in-one claim. All the necessary functions with a well-designed, easy UI."
— AlphaLeaf
Well-rounded platform with solid LLMs
"The team clearly puts their heart and soul into this platform. Really solid extra functionality."
— SlothMachine
Best AI tool I've ever used
"Updates made almost daily, feedback is incredibly fast. Just look at the changelogs — consistency."
— reu0691