How to Analyze the Text: A Practical Guide for 2026
Learn how to analyze the text for themes, sentiment, and insights. This practical guide covers manual and AI methods, plus tools to speed up your workflow.
You open a document planning to “just skim it,” and an hour later you're buried in customer reviews, interview transcripts, competitor landing pages, product notes, and one mysteriously unhinged PDF with six fonts. That's normal. Text analysis looks simple until you have to do it.
The hard part usually isn't access to text. It's turning messy language into decisions you can use. Many organizations either do this manually with highlights and spreadsheets, or they stitch together a pile of disconnected apps for summaries, extraction, classification, writing, and search. That works right up until you need consistency.
So You Have a Wall of Text to Analyze
A wall of text is rarely just a wall of text. It's usually a backlog of unresolved questions. What are customers complaining about? Which competitor claims keep repeating? Where does the messaging feel weak? Which ideas are overused, and which ones are missing?
The old workflow is familiar. Read a bit. Copy chunks into notes. Paste snippets into one AI tool for summaries, another for sentiment, another for keyword clustering, then try to remember where you saved the useful answer. By the end, the analysis itself is fine, but the process is chaos.
That chaos matters more now because text analysis isn't just about classic keyword hunting anymore. A newer angle in search is information gain. The gap isn't always “we forgot a keyword.” Sometimes the gap is “we said nothing original.” A 2026 analysis noted the shift from keyword gaps to semantic, intent, and value gaps for AI search and answer engines in .

Why text feels harder than it should
A lot of people think they need a fancy model first. Usually, they need a better workflow first.
Here's where analysis tends to break:
- Too much raw material. Reviews, transcripts, PDFs, blog posts, and docs don't arrive in a clean format.
- No clear question. If you don't know what you're looking for, every paragraph feels equally important.
- Tool switching. Context gets lost every time you move text between tabs.
- Shallow outputs. A summary tells you what was said. It often doesn't tell you what matters.
Practical rule: Don't start by asking “What does this text say?” Start by asking “What decision am I trying to make from this text?”
There's also a hidden issue. Many guides on how to analyze the text still treat everything like a keyword exercise. That misses structure, tone, recurring claims, contradiction, and missing information. If you've ever studied speeches, ads, or media, you've seen this broader lens before. A good example is this , which is useful because it pushes you beyond surface wording into intent, form, and effect.
What a modern workflow should feel like
A useful workflow should let you do all of this without rebuilding context every ten minutes:
That's the difference between “I read a lot” and “I analyzed the text.”
Starting with a Smart Read-Through
You open a folder with fifty survey responses, three competitor pages, a product spec, and two weeks of support tickets. An hour later, you have highlights everywhere and nothing you can use. That usually means the first pass had no job to do.
A smart read-through is scoped. Before reading closely, define what you need to extract and what can be ignored. The order matters. Strong analysts set the question first, screen the material against that question, then capture notes in a way that can feed later theme, sentiment, and quantitative work. In a disconnected workflow, that discipline is easy to lose because your notes live in one tool, your excerpts in another, and your synthesis somewhere else. In Zemith, the same pass can become the foundation for the rest of the analysis instead of disposable prep work.
Read for a decision
Different text sets call for different first-pass questions. A support queue pushes you toward friction, root causes, and repeated wording. A whitepaper calls for claims, evidence, and gaps. Competitor copy is often about positioning, proof, and what they avoid saying.
The practical test is simple. If your question would not change a business decision, it is too broad.
Use prompts that force selectivity:
- Decision question. What choice should this reading inform?
- Signal question. What phrases, claims, or patterns count as useful evidence?
- Noise question. What content can you ignore on the first pass?
- Output question. What are you producing at the end: a memo, a content brief, a risk list, or a set of annotated excerpts?
That framing changes the read-through immediately. You stop collecting interesting lines and start collecting usable ones.
What a strong first pass looks like
A good first pass is light, but it is not casual. The goal is orientation with structure.
- Scan the document shape. Headings, repeated sections, citations, footnotes, tables, and abrupt shifts in tone.
- Mark extraction points. Definitions, objections, promises, constraints, recommendations, pricing references, and exceptions.
- Ask targeted questions against the text. “Pull every mention of implementation risk.” “List statements that sound like proof but lack evidence.” “Group comments about setup confusion.”
- Store notes in a form you can reuse. Tagged excerpts beat raw highlights every time.
Integrated tooling saves real time. In a manual workflow, analysts often skim in one tab, copy quotes into a doc, sort notes in a spreadsheet, then re-read the source to recover context. Zemith reduces that churn because the initial read, excerpting, tagging, and follow-up questioning can happen in one place. That makes the first pass more disciplined, not just faster.
If you want to sharpen the manual side of this skill, these hold up well in real document work.
Common mistakes on the first read
Three habits waste time early:
- Reading in presentation order instead of extraction order. Authors write to persuade or explain. Analysts read to locate signals.
- Highlighting anything that sounds important. Broad highlighting feels productive and produces weak notes.
- Treating one vivid paragraph as representative. Strong wording gets attention. Repeated wording across the corpus is usually more useful.
The first read should leave you with a map, not a verdict. If the notes are clean, the later layers of analysis become much easier to run inside one workflow instead of rebuilding context at every stage.
Finding the Themes Hiding in Plain Sight
Once you understand the material at a basic level, the substantive work begins. Themes aren't just “topics mentioned a lot.” They're recurring patterns that connect separate pieces of text in a meaningful way. That distinction saves you from a lot of fake insight.
If you've ever done the highlighter-and-spreadsheet routine, you know the pain. You color code a transcript, dump quotes into a sheet, invent category names on the fly, then later realize “onboarding confusion,” “setup issues,” and “implementation friction” were all the same theme wearing different hats.

What coding actually means
In plain English, coding means assigning labels to chunks of text so you can compare them later. That's it. You're not trying to sound academic. You're creating a system that lets you ask, “Where does this idea show up, how often, in what context, and alongside what other ideas?”
One study on software projects highlights thematic analysis as the core qualitative technique and warns against treating frequency as insight without validation. It also recommends a clear codebook and explicit theme definitions before drawing business conclusions in .
A practical codebook that won't collapse
You do not need an elaborate taxonomy on day one. You do need rules.
A useful codebook usually includes:
- Theme name. Short and plain. “Pricing confusion” beats “commercial ambiguity.”
- Definition. What belongs inside the theme.
- Boundary. What does not belong.
- Example text. A sentence or phrase that clearly fits.
- Decision note. Why the theme matters.
Here's a simple way to keep themes clean:
Watch for this: A repeated word is not automatically a repeated idea. People can describe the same problem with very different language.
How to find themes without drowning in tabs
An integrated workspace proves useful. Instead of analyzing one file at a time, you can keep related interviews, reviews, or competitor materials in one place and query them together. In practice, that means you can upload a set of documents, ask for recurring feature requests, compare language by audience segment, and then trace each theme back to the source passages.
That's a cleaner way to analyze the text than manually copying excerpts between apps. If you want a more detailed walkthrough of the logic behind this process, this guide on is worth reviewing.
What works and what doesn't
What works:
- Grouping similar phrases under one defined theme
- Revising theme names after reviewing more evidence
- Checking whether a theme helps a decision
- Comparing themes across document types
What doesn't:
- Naming themes too early
- Treating a dramatic quote as representative
- Mixing complaints, requests, and outcomes in one bucket
- Trusting frequency without checking context
The easiest mistake here is building a theme system that looks organized but doesn't survive contact with the text. If you can't explain why a quote belongs in a category, your theme needs work.
Gauging the Mood with Sentiment Analysis
Themes tell you what people discuss. Sentiment tells you how they feel while discussing it. That sounds straightforward until you feed a sarcastic review into a model and it politely informs you that “Amazing, another broken update” appears positive. Machines are brave. Sarcasm is braver.
Still, sentiment analysis is useful when you treat it as triage, not gospel. It helps you sort large volumes of text quickly, identify likely friction points, and flag the items that deserve a closer human read.
Here's a visual way to think about sentiment outputs at a glance.

Sentiment is more than positive and negative
Basic sentiment labels are a start, but they're often too blunt for real decisions. “Negative” could mean angry, disappointed, confused, anxious, or skeptical. Those are very different operational signals.
For example:
- Frustration often points to broken flows, support pain, or hidden complexity.
- Confusion usually signals unclear messaging, weak onboarding, or technical wording.
- Skepticism tends to show up around claims, pricing, guarantees, or trust.
- Excitement can reveal language worth mirroring in campaigns or product copy.
That's why I prefer asking for justification, not just a label. If you analyze the text and request the sentences behind the classification, you get something you can audit.
A smarter way to use sentiment
Sentiment works best as a filtering layer. Use it to sort first, interpret second.
Try prompts and workflows like these:
- Customer review pass. Classify sentiment and extract the lines that support the judgment.
- Support ticket sweep. Identify messages showing urgency, frustration, or confusion.
- Competitor review scan. Separate praise for product strengths from complaints about service gaps.
- Campaign feedback readout. Distinguish indifference from actual dislike.
A useful semantic lens also helps here because emotion often hides inside phrasing, implication, and context rather than obvious positive or negative words. This overview of is helpful if you want to go beyond basic polarity.
This short video is a good companion if you want another angle on how sentiment fits into text interpretation.
Where sentiment usually fails
Sentiment analysis struggles when text has any of the following:
- Sarcasm. Humans still win this round.
- Mixed feelings. “The product is powerful but setup was miserable.”
- Domain language. Technical terms can look neutral while carrying strong implications.
- Polite negativity. B2B users often understate frustration.
A “neutral” label often means “this needs a human second look,” not “nothing is wrong.”
The biggest mistake is treating sentiment like a verdict. It's a prioritization tool. If it flags documents for review and points you toward the reasons, it's doing its job.
Running the Numbers with Quantitative Analysis
Sooner or later, someone asks for proof. Not vibes. Not “it feels like customers mention this a lot.” Actual patterns. That's where quantitative text analysis earns its keep.
This doesn't require a statistics degree. It requires a few useful concepts and the discipline to ask the right question. Word frequency, phrase frequency, co-occurrence, and repeated framing can tell you a lot about how language is being used. They can also reveal when your content sounds like every other company's content, which is never the goal unless your brand strategy is “confidently interchangeable.”

Why raw counts can mislead
Language is skewed. A small set of words does most of the heavy lifting. In statistical word analysis, a Zipfian distribution means the most common words appear far more often than the rest. One analysis found that the top 625 words accounted for 80% of all word usage, while the top 20 made up nearly one-third, as described in .
That's why raw counts alone aren't enough. Frequent words can dominate a corpus without telling you much. Analysts rely on methods like term frequency, TF-IDF, collocation analysis, and n-grams because they help separate generic repetition from meaningful pattern.
The metrics that matter most
For practical work, I'd focus on four quantitative views:
A few prompt ideas make this much easier:
- Frequency scan. List the most frequent non-trivial words and group close variants.
- Trigram extraction. Find repeated three-word phrases after removing stop words.
- Framing analysis. Show which adjectives most often appear near the product name.
- Competitor contrast. Compare recurring phrases across two sets of articles.
If you want a broader foundation for these methods, this guide to gives useful context on how to inspect patterns before jumping to conclusions.
What numbers can actually help you do
Quantitative analysis is great for tasks like these:
- Content strategy. Identify phrases competitors repeat so you can decide whether to match or differentiate.
- Voice cleanup. Catch filler wording such as “synergistic,” or “game-changing” before they colonize every paragraph.
- SEO and AI search prep. Surface the recurring entities, modifiers, and question patterns that shape discoverability.
- Product research. See which feature terms appear with praise, confusion, or complaints.
Useful constraint: If a numeric pattern doesn't change a writing, product, or research decision, it's trivia.
The point of counting language isn't to pretend text is only math. It's to support interpretation with evidence.
From Analysis to Action Your Integrated Workflow
You collect twenty competitor pages, a handful of customer reviews, and a few sales call notes. An hour later, the text is spread across tabs, a notes app, a spreadsheet, and a chat window that no longer remembers what you uploaded first. The analysis is not the hard part at that point. Keeping context intact is.
A workable text analysis process is staged and connected. Start with a decision that needs support. Gather the relevant text in one place. Review it for claims, themes, tone, and repeated language. Then turn those findings into an output someone can act on.
Here is a practical version of that workflow for competitor research.
A practical example with one workspace
Use a question that forces focus: What themes, claims, emotional cues, and content gaps show up across this competitor's materials?
Then run the work in order:
Create a project for the competitor
Pull in blog posts, landing pages, comparison pages, support docs, and any sales or review text you have. Keeping the source material together saves a lot of rework later.Run a fast read-through and summary pass
Capture the main claim, intended audience, and repeated wording for each asset. Short notes are enough if they stay tied to the source.Group recurring themes
Consolidate similar language under a small set of labels such as onboarding, migration risk, reporting, integrations, or cost control. Tight theme definitions matter here. Loose labels create noisy findings.Review sentiment and stance
Look beyond positive or negative wording. Check for confidence, urgency, hedging, credibility signals, and the places where customer pain is addressed clearly or dodged.Add quantitative checks
Scan for repeated phrases, term frequency, common modifiers, and claim patterns. Counts will not explain the whole story, but they are useful for confirming what your close read already suggests.Convert findings into a deliverable
Build the content brief, messaging memo, comparison page outline, or product note while the evidence is still fresh.
This workflow sounds simple because it is. The hard part is staying organized while the project grows.
Why an integrated setup changes the quality of the work
In practice, text analysis falls apart when the workflow is split across too many tools. Notes lose their source. Summaries get copied without the paragraph they came from. A good insight shows up in the analysis tool, then disappears when the drafting starts.
I have seen this happen in content audits and voice-of-customer work over and over. The team does the reading, tagging, and counting correctly, but the handoff from analysis to action is messy, so the final recommendation gets watered down.
Zemith helps because the workflow can stay inside one workspace. You can keep source files, cross-document chat, notes, drafts, and whiteboards connected to the same project context. That changes the job from juggling tools to evaluating text. If you want a broader view of how that kind of setup works, this guide to is a useful reference.
The trade-off is straightforward. A single platform will shape how you organize the work, and some analysts like building their own stack. But for repeated text analysis tasks, consistency usually beats tool-hopping.
What a useful final output looks like
A finished analysis should give someone enough evidence to make a decision. In most cases, that means including:
- Core themes with clear definitions
- Text evidence that supports each theme or claim
- Sentiment or stance notes where tone affects interpretation
- Quantitative patterns that confirm or challenge the read
- Recommended action tied to a real next step
That last part separates analysis from documentation.
A stack of observations is not yet useful. A recommendation is useful: publish the missing comparison page, rewrite onboarding copy to address a repeated objection, reduce vague benefit language, or build a stronger point of view around the feature competitors keep treating as table stakes.
If you are tired of working across too many tabs, gives you one place to keep research, document chat, drafting, and synthesis connected so the analysis leads to action.
Explore Zemith Features
Every top AI. One subscription.
ChatGPT, Claude, Gemini, DeepSeek, Grok & 25+ more












Always on, real-time AI.
Voice + screen share · instant answers
What's the best way to learn a new language?
Immersion and spaced repetition work best. Try consuming media in your target language daily.
Voice + screen share · AI answers in real time
Image Generation
Flux, Nano Banana, Ideogram, Recraft + more

Write at the speed of thought.
AI autocomplete, rewrite & expand on command
Any document. Any format.
PDF, URL, or YouTube → chat, quiz, podcast & more
Video Creation
Veo, Kling, Grok Imagine and more

Text to Speech
Natural AI voices, 30+ languages
Code Generation
Write, debug & explain code
Chat with Documents
Upload PDFs, analyze content
Your AI, in your pocket.
Full access on iOS & Android · synced everywhere
Your infinite AI canvas.
Chat, image, video & motion tools — side by side
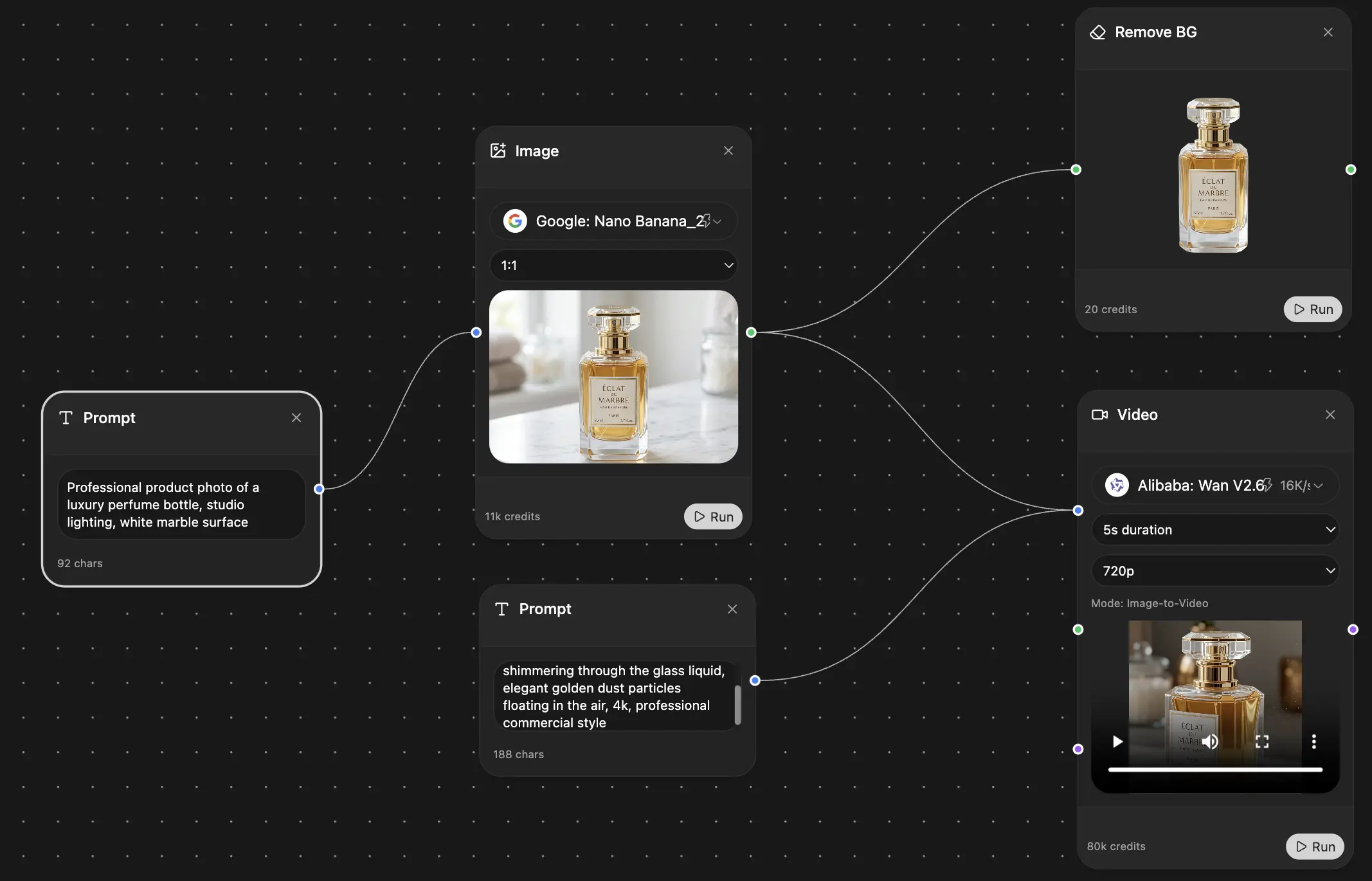
Save hours of work and research
Transparent, High-Value Pricing
Trusted by teams at
Free
No credit card required
- 100 credits daily
- 3 AI models to try
- Basic AI chat
Plus
- 1,000,000 credits/month
- 25+ AI models — GPT, Claude, Gemini, Grok & more
- Agent Mode with web search, computer tools and more
- Creative Studio: image generation and video generation
- Project Library: chat with document, website and youtube, podcast generation, flashcards, reports and more
- Workflow Studio and FocusOS
Professional
- Everything in Plus, and:
- 2,100,000 credits/month
- Pro-exclusive models (Claude Opus, Grok 4, Sonar Pro)
- Motion Tools & Max Mode
- First access to latest features
- Access to additional offers
What Our Users Say
Great Tool after 2 months usage
"I love the way multiple tools they integrated in one platform. Going in the right direction."
— simplyzubair
Best in Kind!
"The quality of data and sheer speed of responses is outstanding. I use this app every day."
— barefootmedicine
Simply awesome
"The credit system is fair, models are perfect, and the discord is very responsive. Quite awesome."
— MarianZ
Great for Document Analysis
"Just works. Simple to use and great for working with documents. Money well spent."
— yerch82
Great AI site with accessible LLMs
"The organization of features is better than all the other sites — even better than ChatGPT."
— sumore
Excellent Tool
"It lives up to the all-in-one claim. All the necessary functions with a well-designed, easy UI."
— AlphaLeaf
Well-rounded platform with solid LLMs
"The team clearly puts their heart and soul into this platform. Really solid extra functionality."
— SlothMachine
Best AI tool I've ever used
"Updates made almost daily, feedback is incredibly fast. Just look at the changelogs — consistency."
— reu0691